
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- MySQL
- CNN
- LSTM
- hm3dsem
- Python
- 그래프 이론
- 딥러닝
- 머신러닝
- real-time object detection
- C++
- dynamic programming
- machine learning
- deep learning
- eecs 498
- image processing
- BFS
- RL
- ubuntu
- hm3d
- Reinforcement Learning
- YoLO
- DP
- r-cnn
- 강화학습
- 백준
- NLP
- dfs
- opencv
- GIT
- AlexNet
- Today
- Total
JINWOOJUNG
ImageNet Classification with Deep Convolutional Neural Networks...(2) 본문
ImageNet Classification with Deep Convolutional Neural Networks...(2)
Jinu_01 2025. 1. 6. 00:41Reducing Overfitting
AlexNet의 경우 6,000만 개의 Parameter를 가지기에, ImageNet의 Subset(Large Datset)으로도 Overfitting이 발생할 수 있다. 본 논문에서는 Overfitting을 막기위한 2가지 방법을 사용한다.
Data Augmentation
Image Dataset에서 Overfitting를 줄이기 위해 Label을 보존한 변형(Data Augmentation)을 많이 사용한다. 본 논문에서는 2가지 주요한 Data Augmentation을 다루며, 매우 작은 연산으로 진행되기에 변형된 Image를 추가적으로 저장할 필요가 없다.
추후 저자가 공지한 것 처럼, Input Image는 잘못된 논문과 달리 227x227x3으로 표현하겠다.
- Translation and Horizontal Reflection
앞서 256x256으로 Rescale 된 Image에 대하여 Random하게 224x224 Patch를 추출하고, 해당 Patch의 Horizontal Reflection(수평 반사)도 생성하여 데이터를 증강시킨 뒤 이를 기반으로 네트워크를 학습시킨다. 증강된 학습 데이터는 높은 상관관계를 가지지만, 학습 데이터의 수를 2048배 증가시킬 수 있다.
테스트 과정에서는 5개(각 모서리 및 중앙)의 224x224 Patch와 그 수평 반사를 생성하여, 10개에 대한 예측의 평균으로 최종 예측을 수행한다.
- RGB Intencsity 조절
학습 데이터 셋에 대하여 RGB Intensity를 조절한다. 이는 학습 데이터 셋의 RGB Pixel Value에 대하여 PCA(주성분분석)을 수행한다. 그리고 학습 이미지에 대하여 계산한 주성분(Principal Component)의 배수를 더해준다. 이때, 배수의 크기는 해당 고유값($\lambda_i$)에 비례하며, 평균이 0이고 표준 편차가 0.1인 가우시안 확률 변수에서 추출된 값($\alpha_i$)에 의해 결정된다.
주성분분석이란 차원을 줄이면서 데이터의 주요 특징을 유지하는 방법이다.
Image에 대한 주성분분석은 RGB 색상에 대한 공분산과 고유 벡터를 계산한다. 이때, 각 색상간의 공분산은 각 색상간의 상관관계를 의미한다. 고유 벡터는 공분산 행렬이 가장 큰 분산을 가지는 방향으로, RGB Pixel Value가 가장 많이 변하는 주요 방향을 의미한다. 예를 들어, [0.5, 0.5, 0.5]의 경우 R,G,B Pixel Value가 같은 배율로 증/감이 됨을 의미한다.
최종적으로 이러한 Augmentation을 하는 이유는 현실에서 발생 가늫안 다양한 조명, 색상을 가지는 하나의 객체에 대하여 다양한 데이터 셋을 생성하여 Overfitting을 줄이고 강인한 모델을 만들기 위함이다. 이때, 아래 수식에 근거하여 더해지는 값의 경우 고유 벡터의 배수이기에 색상간의 상관관계를 유지하면서 색상을 변형시킨다.
최종적으로 Image의 RGB Pixel Value $I_{xy} = [I^R_{xy}, I^G_{xy}, I^B_{xy}]$에 다음과 같은 값이 더해진다.
$$[p_1, p_2, p_3][\alpha_1 \lambda_1, \alpha_2 \lambda_2, \alpha_3 \lambda_3]^T$$
이때, $p_i$는 $i$번째 고유 벡터, $\lambda_i$는 $i$번째 고유 값, $\alpha_i$는 앞서 설명한 가우시안 확률 변수에서 추출된 값이다. $\alpha_i$는 학습할 때 마다 하나의 Image에 대해서 재계산된다.
위와 같은 Data Augmentation의 경우 현실에서 발생 가능한 다양한 조명, 색상을 고려하여 이에 불변하는 객체의 특성을 학습시키기 위함이다.
Dropout
Dropout에 대한 자세한 설명은 다음 포스팅을 참고 바란다. 여기서는 간략하게 설명하고 넘어 갈 것이다.
https://jinwoo-jung.tistory.com/128
Dropout Reduces Underfitting...(1)
Research Paperhttps://arxiv.org/pdf/2303.01500https://jmlr.org/papers/v15/srivastava14a.htmlhttps://arxiv.org/abs/1512.033850. AbstractDropout은 Neural Network에서 Overfitting을 방지하는 정규화로써 사용되고 있다. 본 논문에서는 Dro
jinwoo-jung.com
Dropout은 $p$라는 확률로 특정 뉴런을 비활성화 하고, 해당 뉴런은 Forward, Backward 모두에서 동작하지 않는다. 이를 통해 네트워크는 매번 서로 다른 구조를 가지지만, 가중치는 공유하기 때문에 뉴런의 Co-adaption을 낮출 수 있다.
Co-adaption이란, 뉴런이 특정한 조합으로만 잘 동작하도록 학습하여 일반화 성능이 떨어지고 Overfitting 되는 것을 의미한다. 이는 Dropout을 통해 확률 $p$에 기반하여 뉴런이 비활성화 되기 때문에 특정 뉴런간의 의존성을 줄일 수 있다. 즉, 다양한 뉴런 조합에서도 유용하고 강건한 특징을 학습할 수 있기 때문에 일반화 성능이 높아지고 Overfitting을 줄일 수 있다.
테스트 과정에서는 뉴런의 출력 기댓값을 통일하기 위해 출력값에 $p$를 곱하게 된다. 본 논문에서는 처음 2개의 FC Layer에 Dropout을 적용하였으며, 이를 통해 수렴에 필요한 Iteration을 2배 줄일 수 있었다.
Details of Learning
모델을 학습하는 과정은 다음과 같다.
- Optimization : SGD + Momentum
- Momentum : 0.9
- Batch size : 128
- Weight decay : 0.0005
본 논문에서는 작은 Weight decay를 사용하는 것이 regularizer 분만 아니라 모델의 Training Error를 감소시키는 역할도 함을 확인하였다. 최종적으로 Weight $w$가 Update 되는 과정은 다음과 같다.
Momentum은 기존의 방향을 일정한 비율로 유지시키는 방법이다.
$i+1$ 시점에서 Mini-batch에 대한 평균 Gradient와 이전의 방향인 $v_i$를 일정한 비율로 유지시킨 $v_{i+1}$을 최종적으로 Update하게 된다.
Momentum은 기존 SGD가 중구난방으로 최적점을 찾아가는 것에 대해서 그 진동을 줄이고, 기존의 방향을 일정부분 유지시켜 Local Minimum에 빠지지 않고 최적점에 대한 방향으로 가속을 해주는 방법이다.
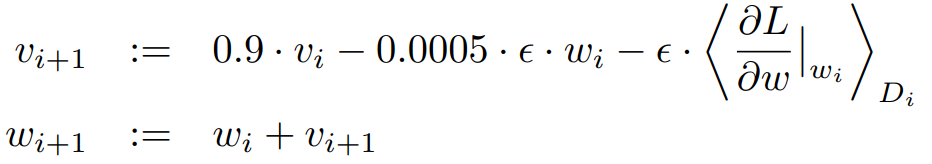
이때, $i$는 Iteration Index, $v$는 Momentum Value, $\varepsilon$는 Learning Rate, $\left< \frac{\partial L}{\partial w}|_{w_i} \right>_{D_i}$는 $i$번째 Batch $D_i$에 대한 평균 Gradient이다.
Weight Initialization의 경우 평균이 0, 표준 편차가 0.01인 Gaussian distribution을 기반으로 초기화 하였다. Bias의 경우 2, 4, 5번째 Conv Layer의 경우 1로 초기화 하여 초기 학습을 가속화 하였으며, 나머지는 0으로 초기화 하였다.
Learning Rate의 경우 전체 Layer에 대하여 동일하게 사용하였으며, 학습 과정에서 검증 에러가 향상되지 않으면 10배 줄이는 방법으로 Heuristic하게 조절하였다. 초기 Learning Rate는 0.01이며 학습 과정에서 총 3번의 감소가 이루어졌다.
Results
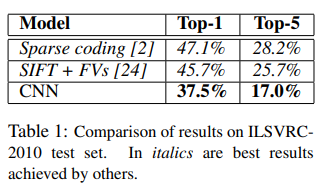
top-1 error는 37.5%, top-5 error는 17.0%로 기존 최고 성능을 보인 수치보다 훨씬 향상된 수치이다. 기존 최고 성능을 보인 모델의 경우 Coding 기반의 모델과 SIFT와 같은 특징들이 결합된 Feature Representation 중 하나인 Fisher Vectors를 학습한 모델이다. 이는 CNN의 성능이 Feauture 기반의 방법보다 훨씬 압도적인 성능을 보임을 의미한다.
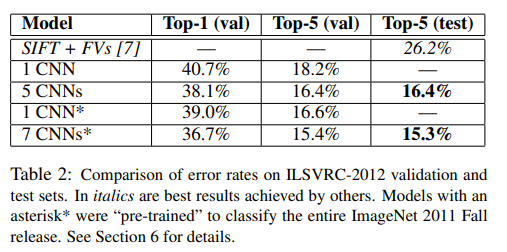
ILSVRC-2012에 제출한 모델의 성능은 다음과 같다. Table 2의 5 CNNs는 비슷한 5개의 CNNs 예측의 평균을 의미한다. *는 본 논문에서 제안한 Network에서 마지막 Pooling Lyaer 이후 하나의 Conv Layer를 추가시킨 CNN에 대하여 ImageNet Fall 2011 Dataset에 대하여 학습시킨 뒤, ILSVRC-2012에 대하여 Fine Tuning 시킨 모델이다.
최종적으로 7 CNNs*는 Top-5 error가 15.3%로 2위인 Feature 기반(FVs 학습)의 모델의 Top-5 error 26.2%보다 월등한 성능을 보인다.
Qualitavie Evaluations

왼쪽은 test image에 대한 모델의 Top-5 Prediction을 시각화 한 것이다. 모델은 Image의 객체가 중심에 위치하지 않아도 객체를 검출하는 것을 확인할 수 있다. 또한, Top-5 Prediciton 모두 합리적인데, 치타의 경우 치타와 유사한 고양이과 클래스로 모두 예측하였다. Cherry와 같은 경우는 사진에서의 초점의 차이의 모호성을 확인할 수 있는데, 해당 Image의 클래스는 Cherry이지만, Image 내 Dalmatian도 존재하여 모델이 Dalmatian에 초점을 맞춰 검출함을 확인할 수 있다.
오른쪽의 경우 1열은 Test Dataset이고, 나머지 2~7열은 모델의 마지막 4096 차원의 Hidden Layer의 Euclidean Distance가 작으면 유사하다고 판단함을 이용하여 가장 유사하다고 판단한 6장의 Image를 나타낸 것이다. Pixel 수준에서는 L2 Distance가 큰데 이는 객체가 서로 다른 자세와 위치를 가지기 때문이다. 하지만 모델은 유사하다고 예측하였으며, 이는 Linear Classifier가 가지는 하나의 Template만 학습할 수 있는 단점을 능가하여 여러가지 Templates를 학습함을 확인할 수 있다.
Discussion
본 논문에서는 Large, Deep CNN을 지도 학습만을 사용하여 매우 어려운 데이터 셋에서 압도적인 성과를 달성하였다. 주목할 점은 하나의 Conv Layer만 제거해도 성능이 저하되며, 이는 Network의 Depth가 모델의 성능에 큰 영향을 줌을 알 수 있다.
본 논문에서 활용하지 않았지만, 네트워크 크기를 상당히 늘릴 수 있을 만큼 충분한 계산 자원을 확보하고, 레이블 된 데이터의 양을 증가시키지 않으면, 레이블이 없는 데이터로 비지도 사전 학습을 하는 것은 성능 향상에 도움이 될 수 있다. 이는 비지도 학습을 통해 Data의 일반적인 패턴, 구조 등을 학습하여 이를 Weight 초기화에 사용하면 효율적인 학습이 가능하게 된다.
Reference
1. https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
2. https://arxiv.org/abs/1409.0575
'딥러닝 > 논문' 카테고리의 다른 글
| Very Deep Convolutional Networks for Large-Scale Image Recognition...(2) (0) | 2025.01.07 |
|---|---|
| Very Deep Convolutional Networks for Large-Scale Image Recognition...(1) (0) | 2025.01.07 |
| ImageNet Classification with Deep Convolutional Neural Networks...(1) (0) | 2025.01.04 |
| Dropout Reduces Underfitting...(2) (0) | 2024.12.31 |
| Dropout Reduces Underfitting...(1) (1) | 2024.12.30 |



