
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Reinforcement Learning
- 머신러닝
- opencv
- Python
- CNN
- YoLO
- hm3dsem
- GIT
- image processing
- ubuntu
- dynamic programming
- CS285
- DP
- 그래프 이론
- machine learning
- RL
- 딥러닝
- C++
- 강화학습
- 백준
- BFS
- r-cnn
- NLP
- deep learning
- AlexNet
- MySQL
- hm3d
- LSTM
- UC Berkeley
- dfs
- Today
- Total
JINWOOJUNG
K-armed Bandit(2) 본문
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar
수강 후 정리를 위한 포스팅입니다.
모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다.
Before This Episode
https://jinwoo-jung.tistory.com/8
K-armed Bandit(1)
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar 수강 후 정리를 위한 포스팅입니다. 모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다. K-armed Bandit 강
jinwoo-jung.tistory.com
Upper Confidence Bounds(UCB)
UCB Algorithm은 potential($U_t(a)$)를 측정하는 알고리즘이다.
이때, $U_t(a)$는 아래의 부등식을 만족한다.
$$P[q_*(a) > Q_t(a)+U_t(a)] \leq p \qquad \Leftrightarrow \qquad P[q_*(a) /leq Q_t(a)+U_t(a)] > p$$
이는 potential을 Sample Avg에 더했을 때, ture mean 보다 작을 확률 P가 특정 확률 p보다 작은 확률을 계산 가능함을 의미한다.
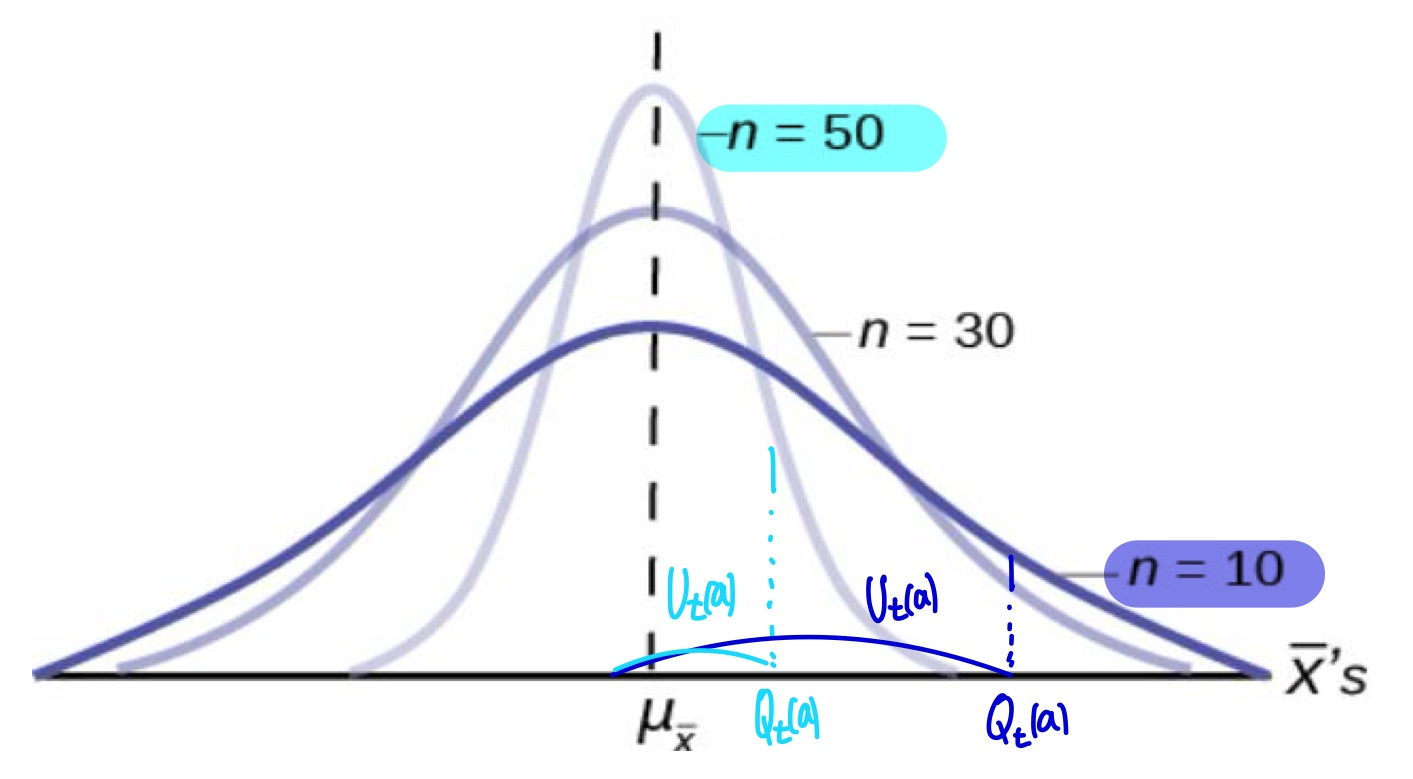
위 그래프를 보면 N이 커질수록 true mean으로 좁아지는 PDF가 형성됨을 알 수 있다. 따라서 $Q_t(a)+U_t(a)$가 $q_*(a)$보다 크기 위해서는 N이 커질수록 더 작은 $U_t(a)$가 필요하다. 따라서 Upper Bound $U_t(a)$는 $N_t(a)$의 함수로써 동작하며, ture mean보다 커질 수 있는 잠재력(potential)을 의미한다.
따라서 UCB Algorithm에서 우리는 항상$A_t(a) = \underset{a}{argmax}[Q_t(a)+U_t(a)]$를 만족하는 $U_t(a)$가 가장 큰 greediest action을 수행한다.
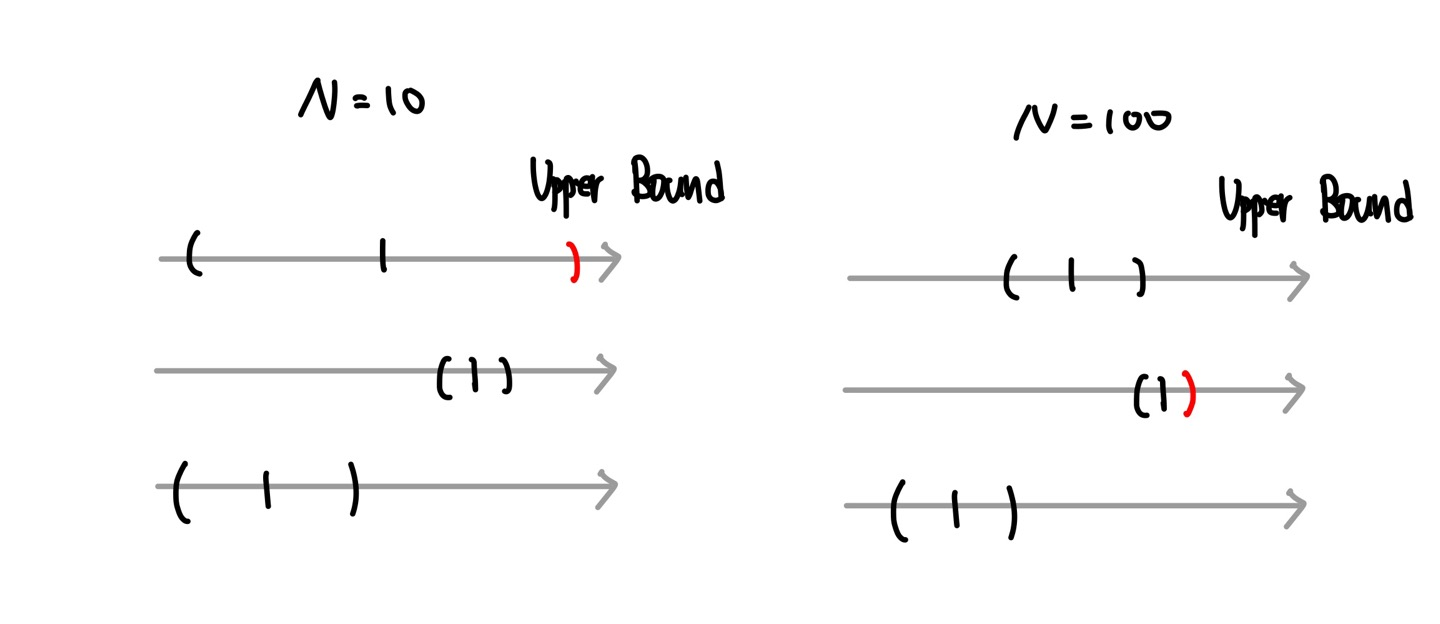
각 machine의 Upper Bound가 다음과 같이 형성되어 있다고 하자. 두번째 machine이 평균이 가장 높아서 좋아 보이지만, N이 작을수록 각 machine의 PDF는 평균을 중심으로 넓게 분포해서 첫 번째 machine의 Upper Bound가 더 크다. 따라서 greedy action이 첫번째 machine으로 수행된다.
N이 증가할수록 PDF는 true mean을 중심으로 모이게 형성되고 따라서 가장 높은 Upper Bound가 두번째 이므로 이를 기준으로 greedy action이 수행된다.
즉, UCB algorithm은 Exploration, Exploitation 모두 적절히 수행하는 알고리즘임을 알 수 있다.
Hoeffding's Inequality
UCB를 정의하기 위해서 Hoeffding's Inequality를 사용한다.
$X_1,X_2,\cdots,X_N$을 iid random variables라 하고 모두 [0,1] 구간에서 bounded된다고 할 때,
Sample Avg $\overline{X}_N = \frac{1}{N}\sum_{i=1}{N}X_i$로 정의된다. $u > 0$일 때,
$$P[E[X] > \overline{X}_N + u] \leq e^{-2Nu^2}$$
이때, $e^{-2Nu^2}$는 매우 작은 확률 $p$로 정의하면, $U_t(a) = \sqrt{\frac{-ln(p)}{2N_t(a)}}$이다.
여기서 iid는 독립 항등 분포를 의미하며, 같은 slot machine은 identically distribution(동일 확률분포)를 지니며, 횟수에 따른 횟수에 따른 각각의 reward는 서로 independent(독립적이다)하다.
'Reinforcement Learning' 카테고리의 다른 글
| Bellman Optimality Equation (0) | 2023.12.30 |
|---|---|
| Markov Decision Process(MDP) (1) | 2023.12.29 |
| Markov Reward Process(MRP) (1) | 2023.12.29 |
| K-armed Bandit(1) (0) | 2023.12.27 |
| Reinforcement Learning (1) | 2023.12.27 |



