
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- hm3dsem
- dynamic programming
- YoLO
- C++
- 백준
- Reinforcement Learning
- MySQL
- opencv
- dfs
- UC Berkeley
- 강화학습
- GIT
- 딥러닝
- image processing
- AlexNet
- CNN
- r-cnn
- deep learning
- NLP
- Python
- RL
- 그래프 이론
- 머신러닝
- DP
- CS285
- ubuntu
- hm3d
- machine learning
- BFS
- LSTM
- Today
- Total
JINWOOJUNG
[ DB ] 데이터베이스...10(SQL...6) 본문
본 포스팅은 인하대학교 최원익교수님의 "데이터베이스설계" 수업에서 진행한 프론트, 백엔드 실습 관련 정리하는 포스팅입니다. 백엔드, 프론트엔드는 전문 분야가 아니기에 공부용으로 올리는 포스팅이며 오류사항이 있을 수 있습니다.
https://jinwoo-jung.tistory.com/108
[ DB ] 데이터베이스...9(SQL...5)
본 포스팅은 인하대학교 최원익교수님의 "데이터베이스설계" 수업에서 진행한 프론트, 백엔드 실습 관련 정리하는 포스팅입니다. 백엔드, 프론트엔드는 전문 분야가 아니기에 공부용으로 올리
jinwoo-jung.com
마지막 SQL 포스팅이다.
집단함수
SQL에서는 COUNT, SUM, MAX, MIN, AVG 등의 집단 함수들이 존재한다. 각 함수의 인자로는 Attribute Name이 들어가며, 각각의 함수의 이름처럼 동작한다.
- 종업원의 급여의 합, 최고 급여, 최저 급여, 평균 급여를 구하시오
질의에서 말하는데로 쉽게 집단 함수를 사용하여 계산할 수 있다.
select sum(Salary), max(Salary), min(Salary), avg(Salary) from employee;
- 'Research' 부서에 있는 모든 종업원들의 급여의 합, 최고 급여, 최저 급여, 평균 급여를 구하시오.
조건문이 있으면, 앞에서 한 것 처럼 WHERE문을 붙이면 된다. 하지만, 조건문을 보면 'Research' 부서에 있는 종업원들의 급여를 찾아와야 한다. 그러면 Department Table의 Dname이 'Research'인 Tuple의 Mgr_ssn을 Employee Table의 Ssn으로 가지는 Tuple을 찾아야 하는데 조건을 설정하는데 어렵다.
이러한 경우, 원하는 Attribute들을 가지는 새로운 Table을 JOIN으로 생성하는 것이 더 효과적이다.
select * from (employee join department on dno = dnumber);
이렇게 하면 Department Table의 Dno와 Employee Table의 Dnumber가 같은 경우 Column이 연결되어 하나의 Table로써 활용할 수 있다. 따라서 이제는 해당 Table에서 Dname이 'Research'인 Tuple만 찾아서 해당 Tuples의 급여의 합, 최고 급여, 최저 급여, 평균 급여를 구하면 된다.
select sum(Salary), max(Salary), min(Salary), avg(Salary) from (EMPLOYEE JOIN DEPARTMENT ON DNO = DNUMBER) where dname = 'Research';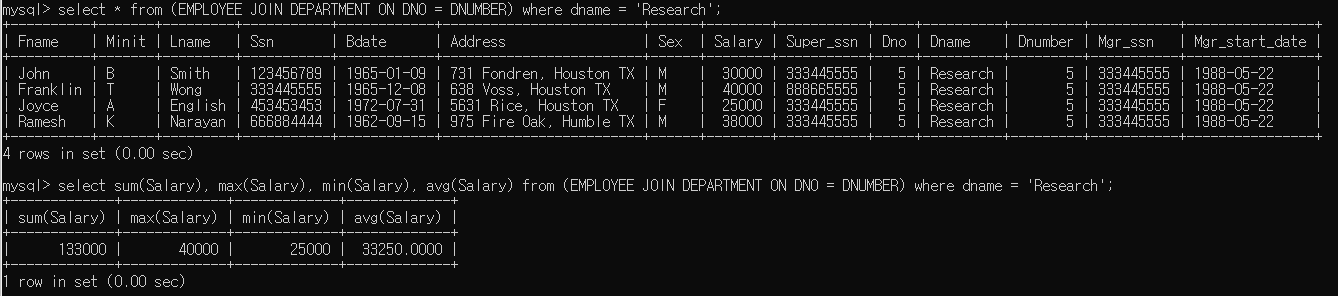
Count 함수에 대하여 조금 더 살펴보자.
- 회사내의 총 종업원의 수를 검색하시오.
Count(*)의 경우 해당 테이블의 Tuple의 수를 반환한다.
select count(*) from employee;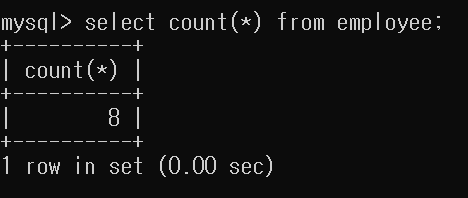
- 'Research' 부서에 속해 있는 종업원의 수를 검색하시오.
select count(*) from employee as e, department as d where d.dname = 'Research' and e.dno = d.dnumber;
- 중복되지 않은 salary 값이 몇 개인지 검색하시오
중복되지 않은 경우는 distinct를 이용해서 해결할 수 있다.
select count(distinct salary) from employee;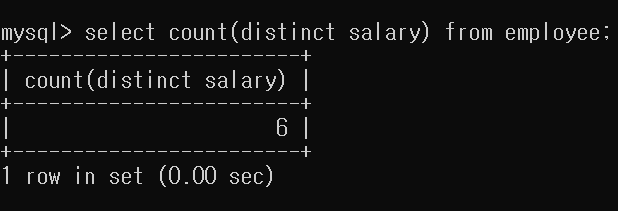
- 둘 이상의 부양가족이 있는 모든 사원의 이름을 검색하시오.
둘 이상임을 판단하기 위해서 count(*)로 ssn = essn인 Tuple의 수를 측정하였고 이는 부양 가족의 수를 의미한다.
select lname, fname from employee where (select count(*) from dependent where ssn = essn) > 2;
Grouping
Grouping은 특정 Attribute의 값이 같은 Tuple을 모아서 Group을 생성하고, 생성된 그룹에 대하여 집단 함수를 적용한다.
- 각 부서에 대해서, 부서 번호, 부서 내에 있는 종업원의 수, 평균 봉급은?
select Dno, Count(*), Avg(Salary) from Employee Group By Dno;
Employee Table의 Dno를 기준으로 Grouping 된 Group 내에서 각각의 집단한수가 적용됨을 확인할 수 있다.
- 각 프로젝트에 대해서 프로젝트 번호, 프로젝트 이름, 그 프로젝트에서 근무하는 사원들의 수를 검색하라.
select Pnumber, pname, count(*) from project, works_on where pnumber = pno group by pnumber, pname;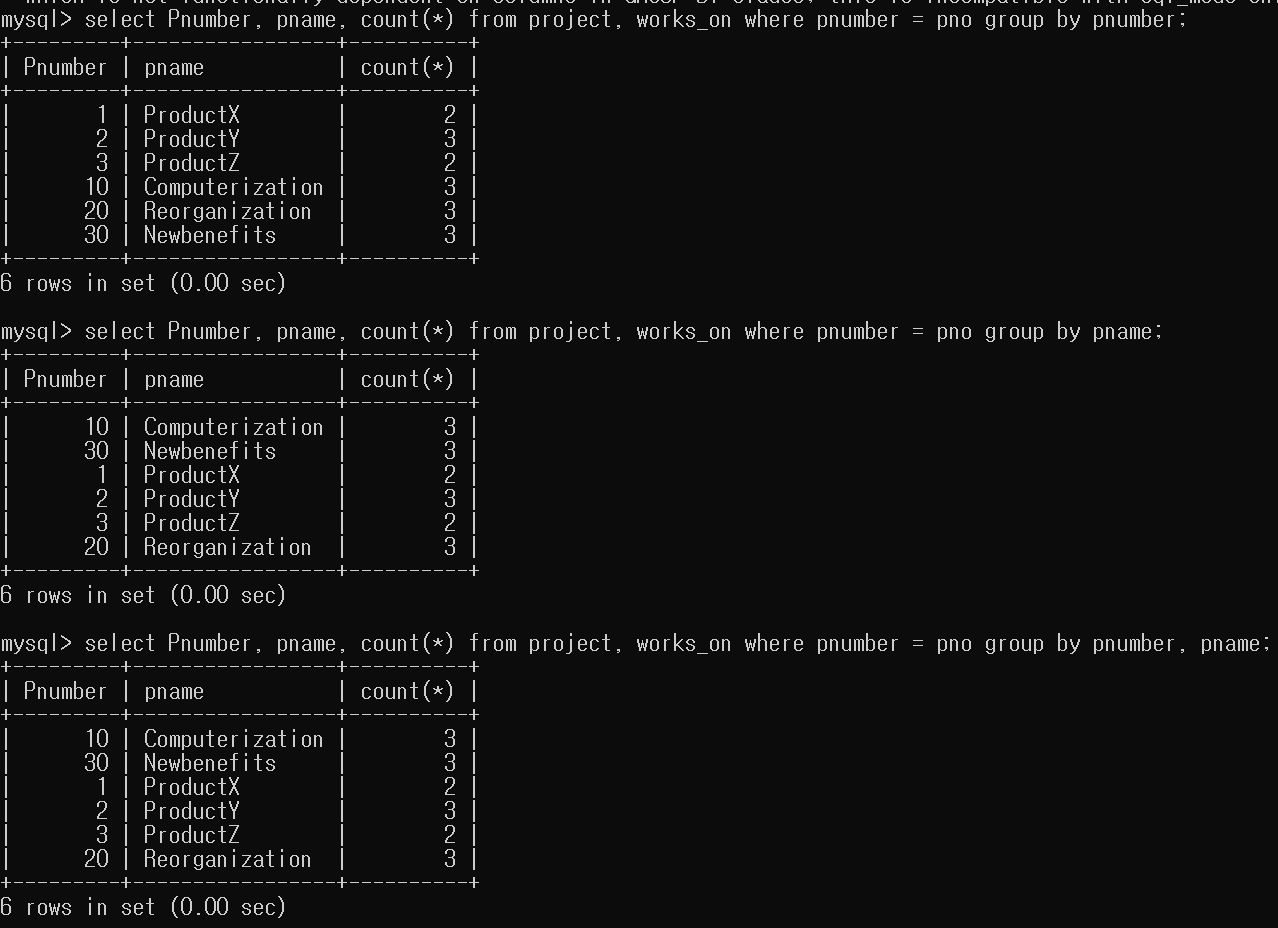
굳이 Pnumber, Pname으로 Group By를 할 필요 없이 둘 중 하나만 해도 결과는 동일하다. 하지만, Ordering의 차이가 존재한다.
그렇다면, Grouping 할 때 조건을 걸어줄 순 없을까?
- 세 명 이상의 사원이 근무하는 각 프로젝트에 대해서 프로젝트 번호, 프로젝트 이름, 프로젝트에서 근무하는 사원의 수를 검색하라.
앞선 질의와 유사하지만, 각 프로젝트에 3명 이상의 사원이 근무해야 한다. 따라서 Having을 통해 GROUP BY로 묶인 Group에 대하여 3명 이상이라는 조건을 걸면 된다.
select Pnumber, Pname, Count(*) from project, works_on where pnumber = pno group by pno having count(*) >= 3;
pno 즉, Pnumber를 기준으로 Grouping한 각 Group에 대하여 Count(*) 집합 함수를 사용해서 Tuple의 개수를 구하고, 해당 개수가 3이상인 조건을 Having을 통해 구현하였다.

- 6명 이상의 사원이 근무하는 각 부서에 대하여 부서번호와 40,000 달러가 넘는 급여를 받는 사원의 수를 검색하라
해당 질의의 동작을 확인하기 위해 일부 Tuple을 추가했다.
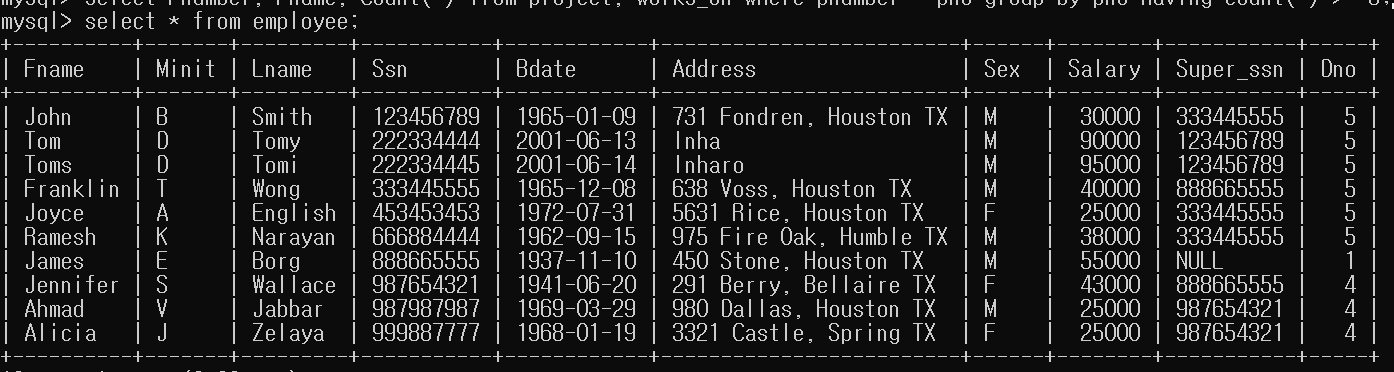
항상 Grouping 할 때는 참조 관계라면, 참조 당하는 Attribute로 진행하는게 더 보기에 좋은 것 같다.
select Dnumber, Count(*) from Department, Employee where Dnumber = Dno and Salary > 40000 and
Dno In (select Dno from Employee group by Dno having count(*) > 5)
group by dnumber;
- 각 프로젝트에 대해서 프로젝트 번호, 프로젝트 이름, 5번 부서에 속하면서 프로젝트에서 근무하는 사원의 수를 검색하라.
Project가 5번 부서에 속하는 것이 아닌 근무자가 5번 부서에 속함을 주의해서 조건절을 생성하자.
select Pnumber, Pname, Count(*)
from Project, Works_on, Employee
where Essn = Ssn and Pnumber = Pno and Dno = 5
group by Pnumber;
'Database' 카테고리의 다른 글
| [ DB ] 데이터베이스...9(SQL...5) (0) | 2024.10.16 |
|---|---|
| [ DB ] 데이터베이스...8(SQL...4) (0) | 2024.10.12 |
| [ DB ] 데이터베이스...7(SQL...3) (0) | 2024.10.12 |
| [ DB ] 데이터베이스...6(SQL...2) (4) | 2024.10.12 |
| [ DB ] 데이터베이스...5(SQL...1) (2) | 2024.10.11 |



