
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- ubuntu
- 그래프 이론
- 딥러닝
- UC Berkeley
- 머신러닝
- hm3d
- 백준
- C++
- CS285
- image processing
- dfs
- DP
- LSTM
- Python
- NLP
- 강화학습
- hm3dsem
- opencv
- GIT
- YoLO
- r-cnn
- dynamic programming
- CNN
- deep learning
- AlexNet
- machine learning
- Reinforcement Learning
- BFS
- RL
- MySQL
- Today
- Total
JINWOOJUNG
[ 컴퓨터 비전 ] Ch5. Deep Learning...5 본문
본 컴퓨터 비전 개념과 기법들에 대한 공부를 진행하면서 배운 내용들을 중심으로 정리한 포스팅입니다.
책은 Computer Vision: Algorithms and Applications를 기반으로 공부하였습니다.
또한, 인하대학교 박인규 교수님의 컴퓨터 비전 과목을 기반으로 제작된 포스팅입니다.
https://jinwoo-jung.tistory.com/114
[ 컴퓨터 비전 ] Ch5. Deep Learning...4
본 컴퓨터 비전 개념과 기법들에 대한 공부를 진행하면서 배운 내용들을 중심으로 정리한 포스팅입니다. 책은 Computer Vision: Algorithms and Applications를 기반으로 공부하였습니다.또한, 인하대학교
jinwoo-jung.com
Recognition(인식)
Recognition Task는 다양한 Task를 포괄한 영상을 식별하고 분석하는 Task이다. Recognition에 속하는 다양한 Task에 대해서 간단하게 알아보자.
Identification(1:N)
Identification은 주어진 데이터에서 특정 개체가 N개의 Class 중 특정 Class에 속하는지 식별하는 Task이다. 따라서 1:N Task임을 알 수 있다. 왼쪽 사진과 같이 주어진 영상에서 원형으로 표현되는 특정 개체가 Lamp인지 식별하는 Task가 Identification이다.
Detection
Detection은 주어진 데이터에서 특정 개체가 어디에 있는지 검출하는 Task이다. 이는 해당 객체가 어떤 Class인지 분류하는 Classification과 해당 객체의 위치를 추정해서 Bounding Box 등으로 표현하는 Localization를 포함하는 Task이다.
사람이 어디있는지 검출하는 Task는 주어진 오른쪽 영상에서 사람의 Class에 속하는 객체를 찾아서 위치를 나타낸다.


Verification(1:1)
Verification은 해당 객체가 특정 Class에 속하는지 검증하는 Task 입니다. 이는 Identification과 달리, 특정 Class 인지 아닌지만 판단하면 되서 1:1 Task 이다.
왼쪽 사진에 대하여 원형으로 표현된 객체가 Potala Palace(특정 Class 예시)에 속하는지 검증하는 것이 Verification이다.
Object Categorization(Classification)
Object Categorization은 Classification이라고 불리며, 주어진 데이터에서 객체가 어떤 Class에 속하는지 판단하는 Task이다. 오른쪽 영상과 같이 각각의 객체에 대하여 Class를 분류하는 것이 Classification이다.

Scene / Context Categorization
Object가 아닌 Scene / Context Categorization은 Categorization 하는 단위의 차이로, Object Categorization의 High Level Task이다. 이는 Object 등의 구조적인 관계를 기반으로 영상의 전체적인 장면 자체를 Categorization 하는 Task 이다.
Activity / Event Recognition
Activity / Event Recognition는 특정 시간적/공간적 패턴을 기반으로 사람의 활동이나 사건을 탐지하고 분류하는 Task이다. 즉, 동적인 상황은 인식하는 Task라고 할 수 있다.


사람의 눈으로는 이러한 Task를 매우 쉽게 수행할 수 있다. 하지만 왜 Computer Vision Task로써는 힘들까? 여러 이유가 있겠지만, 물체의 크기 / 원근 왜곡 / 유사한 패턴의 반복 / 조명에 따른 Apperance 차이 / View Point에 따른 형상의 차이 / Occlusion / Noise / Scale / Blur 등을 들 수 있다.
Recognition using SIFT Matching
우리는 Rotation, Scale에 강건한 Feature Extraction Algorithm SIFT를 배웠다. 그렇다면, SIFT Matching을 통해 Recognition Task를 수행할 수 없을까?
SIFT Matching은 Object Isntance 즉, 객체 하나하나를 검출하는데는 꽤 효과적이다. 하지만 Object Categorization 은 좋지 않은 성능을 가진다. 다음과 같이 "Chair" Category에 속하는 서로 다른 Appearence, Shape 등을 가지는 3개의 Object Instance가 있다고 하자. 그렇다면, SIFT Feature Descriptor는 각각의 Instance에 대해 서로 다르게 생성 될 것이고, 이는 동일한 Category로 Categorization 할 수 없다.

Matters in Recognition
Recognition을 위해서는 어떠한 방법론적인 도구가 필요할까?
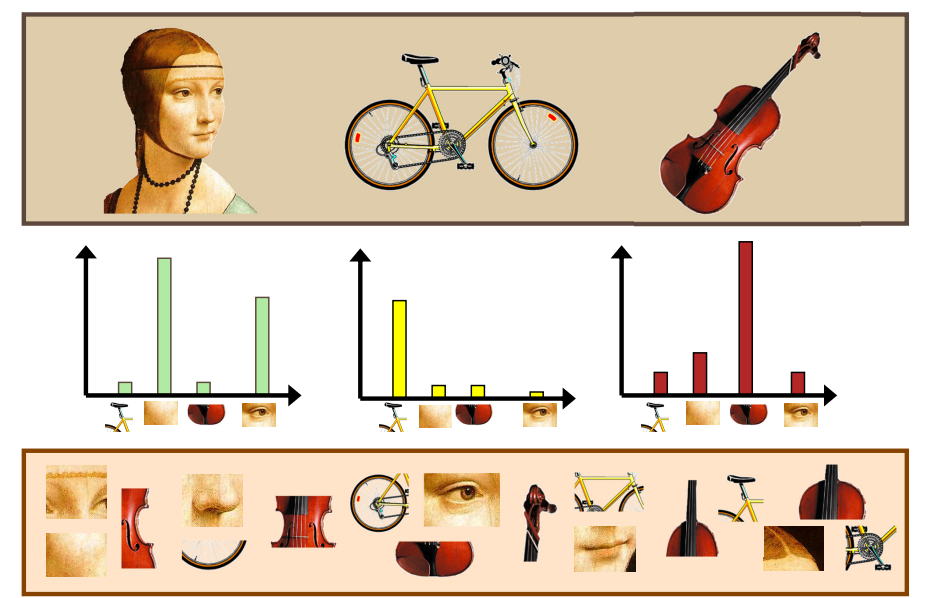
먼저 Learning Techniques이다. Recognition을 위한 Classifier이나 Inference Method를 선택해야 한다.
다음으론 Representation으로, Feature를 Vector 하여 표현하는 방법이다. 사람이 만든 알고리즘에 의한 방법(Hand-crafted)는 SIFT, HoG 등의 Low Level, Bag of words, sliding window 등의 Mid Level, Contectual Dependece 등의 High Level이 존재한다. Deep Learning으로 넘어가면서 Backbone Network에서 CNN이 Feature를 추출하는 것도 이에 속한다. 이는 CNN의 Parameter를 결정하는 것이라 할 수 있는데, 영상의 최적인 Feature를 뽑아내는 방법인 CNN Parameter를 Data를 통해 학습하는 것이다.
마지막으론 Data이다. Data는 많으면 많을수록 좋지만, 이를 하나하나 Annotation(Labeling) 하는 것은 또 다른 문제이다.
Datasets
Data의 경우 수많은 Dataset이 만들어져 사용되고 있다.
PASCAL VOC Challenge
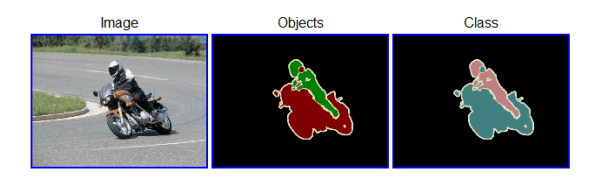
PASCAL VOC Dataset은 2009년에 나온 Dataset으로, aeroplane(비행기)부터 TV/monitor까지 총 20개의 Object Categories를 가지는 Dataset이다. 해당 Dataset을 이용한 Challenge가 열렸는데, Classification, Detection, Segmentation Challenge가 진행되었다.
Large Scale Visual Recognition Challenge(ILSVRC)
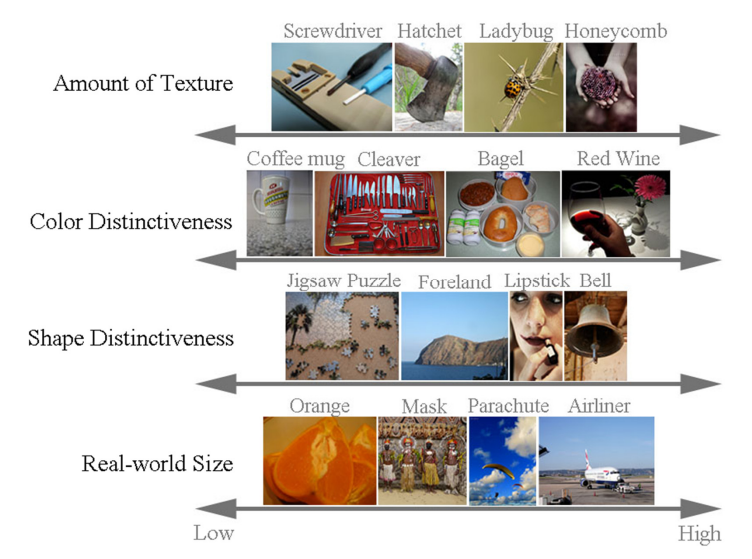
ILSVRC는 2010~2017년도에 진행된 Challenge로, IMAGENET을 이용한 Challenge 입니다. IMAGENET은 1000개의 Object Categories와 1,431,167개의 Classification을 위한 Image로 구성되어 있습니다. 특히 Object Category의 경우 단순히 "Bird"가 아닌 개의 세부 종류(Ex Flamingo, Cock, $\cdots$)등으로 세분화(계층화) 된 Category를 가지고 있습니다. 또한, 수많은 Data가 서로다른 다양한 정도의 표현을 가지고 있습니다. 즉, Color Distinctiveness(색상의 변화)를 살펴보면 매우 낮은 단색을 가지는 Data도 있지만, 다양한 색이 조화를 이루는 Data도 존재하는 등 다양한 Data로 구성되어 있습니다.

Learning Techniques
Image Classifier
Image Classification을 위한 Image Classifier를 살펴보자.
$f$라고 표현되는 Image Classifier는 Input으로 영상을 Output으로 영상의 Class를 반환하는 구조이다. 이때, 동일한 데이터가 여러 범주에 속할 수 있기에 Label(Class)는 하나 혹은 여러개의 Discrete Labels로 할당될 수 있다.

Training & Testing Classifier
Classifier를 학습시키는 과정은 Machin Learning & Supervise Learning으로 진행된다.
Labeled Image로 구성된 Dataset을 기반으로 학습시킨 Classifier는 Test Image로 검증된다. 이때, Machine Learning이기에 Train Dataset으로 부터 Classifier Model이 추출한 Feature Vector를 기반으로 학습된 Classifier를 이용해서 Test Dataset을 예측하여 정답과 비교하여 해당 Classifier의 성능을 검증한다.

Classifier는 KNN, Linear Classifier, SVM 등 여러가지 Model이 사용된다. 또한, AlexNet과 같은 Deep Neural Network(DNN)도 Classifier Model에 속하는데, 마지막 Fully Connected Layer를 보면 Classification을 해야하는 Category의 개수(1000)만큼의 뉴런으로 구성됨을 확인할 수 있다. 이때, 마지막 Layer는 Softmax를 거쳐 각 Class에 속할 확률 값을 반환합니다.

Losses for Image Classification
앞서 Model의 학습 과정에서 Loss가 작아지는 방향으로 Parameter를 학습시킨다고 배웠다. Image Classification에서도 Loss를 정의하여 Loss가 줄어드는 방향으로 Classifier를 학습시킨다.
Multiclass SVM Loss
SVM(Support Vector Machine)은 Classification 과정에서 Decision Boundary를 설정할 때, 데이터와 경계 사이의 Margin을 최대화하는 방법을 사용한다. 이처럼 Multiclass SVM Loss는 정답 Class의 Score가 다른 Score보다 Margin보다 높도록 설정하는 방식으로 동작한다.
오른쪽 아래 수식을 잘 이해하면 되는데, $s_j$는 $j \neq y_i$인 Class Score, $y_i$는 정답 Class Score이다. 즉, SVM Loss는 정답 Class Score가 다른 것보다 Margin만큼 더 커야 Loss를 0으로 할당한다. 아래 예시에는 Margin이 1이 되는 것이다.

고양이 영상이 Input으로 들어왔을 때, $y_i$는 Cat이 된다. 따라서 아래 수식에 근거하여 Loss를 계산 해 보면 2.9이다.
차 영상이 Input으로 들어왔을 때, Car Class Score가 4.9이고, 나머지 Score는 전부 Margin(1)이상 차이난다. 따라서 Loss는 0이 된다.


Input이 개구리일 때 Loss는 12.9로 가장 Worst Case임을 알 수 있다. 최종적으로 Loss는 평균으로 계산되기에 구하면 5.27이 되며, 이 Loss를 Minimize 하는 방향으로 Classifier는 학습하게 된다.


Softmax Classifier
먼저 Softmax Classifier 부터 알아보자.
앞서 Sigmoid Function은 0~1의 범위를 가져 특정 Class를 가질 확률을 의미한다고 배웠다. 이는 주로 이진 분류에 활용된다.
Softmax Classifier는 다중 클래스 분류에 활용되며, Maximum을 Soft하게 즉, 각 Class에 속할 확률을 반환하는 Classifier이다.
Input 영상에 대하여 Classifier Score는 아래와 같이 정규화 되지 않은 로그 확률(Unnormalized Log Probability)로 표현된다. 이를 Exponential 한 결과가 $exp(s_i)$이며, 이는 Unnormalized Probability이다. Softmax Function은 각 Class에 대한 Unnormalized Probability를 모든 Class에 대한 Unnormalized Probability의 합으로 나눈 확률값으로 정규화 된 확률이다.

Cross-Entropy Loss
Softmax Classifier를 학습시키기 위해서 Cross-Entropy Loss가 사용된다.
Loss는 정답과 예측값의 차이값으로 표현되기도 한다. 여기서 Softmax Function은 해당 Class에 속할 확률 $p_i$를 나타내며, 정답 Label $y_i$는 One-Hot Encodding 된 형태로 정답 Label만 1, 나머지는 0이다. 따라서 Loss는 예측한 확률과 정답일 확률의 차이로 정의할 수 있고, 이는 정답 확률과 Softmax를 통해 계산된 확률의 유사도를 비교한 것이다.
이때, Entrophy는 복잡도로 해석할 수 있는데, 이는 확률 변수가 가지는 값(확률을 가지는 Class)가 많을 수록 커진다.
$$ Entrophy = - \sum P_i log(P_i)$$
위와 같이 정의되는 Entrophy에서 log 밖의 있는 $P_i$는 $y_i$를, log 안의 $P_i$는 $p_i$를 의미한다. 따라서 정답 Class가 아니면 $y_i$는 모두 0이 되므로, 다음과 같이 재 정의할 수 있다.
$$ Entrophy = - \sum log(p_{y_i}) $$
최종적으로 Cross-Entropy Loss는 아래 식으로 정의되며, Regularization Term을 포함한다. 이는 Softmax로 계산된 확률과 정답일 확률의 유사도(차이)를 의미하며, 해당 Loss가 작아지는 방향으로 Softmax Classifier는 학습하게 된다.

Representation
Bag of Words(BoW)
Feature를 표현하는 방법 중 하나는 BoW이다.
BoW는 영상을 표현할 때, 영상의 일부(요소, Visual Pattern, $\cdots$)를 Word로 정의하여 Words의 모음(Bag of 'Words')으로 Image Feature를 표현하는 방법이다.

이는 Documents의 유사성을 비교하는 방법에서 착안된 방법이다. Document에 빈도수가 높은 Word를 추출하여 하나의 집합(BoW)로 만들어 Document 전체를 표현하는 방법입니다. 이는 서로다른 Documents를 비교하는데 활용됩니다. 아래의 경우 BoW의 차이가 심하므로 상이한 Document로 판단 가능합니다.

이를 Computer Vision Task로 확장시키면, Visual Word로 BoW를 수행하며 이때 Visual Word는 Feature Vector가 됩니다.

아래와 같이 Visual Word를 생성했다면, 각각의 영상을 표현하기 위해서는 해당 영상에서의 Visual Word Histogram을 생성함으로써 영상을 Visual Word로 표현할 수 있다. 따라서 Image Representation을 위해선 어떻게 하면 적절한 Visual Words를 생성할 수 있을지 고민해야 한다.
Feature Detection
Visual Word로 활용되는 Feature Vector를 검출하는 방법은 다양한 방법이 있다.
먼저 Sliding Window는 영상 전체에 대하여 Window를 Slide 해가면서 윈도우 내 화소들의 분포를 기반으로 Virtual Word를 생성하는 기법이다. 하지만 영상의 Resolution이 커질수록 Window가 많아지는데 이는 수많은 연산 및 Cost를 요구하게 된다. 따라서 Window를 Slide하는 것이 아닌 Regular Grid를 생성해서 Virtual Word를 생성하는 방법이 Regular Grid이다.
Local Feature를 검출하는 방법은 이전에 학습한 SIFT를 확장시킨 방법이 있다. SIFT를 기반으로 검출한 Feature의 Scale 정보에 따른 Sub Window를 생성해 해당 Window 내 Gradient Histogram 등 분포를 추출하여 Visual Word를 생성하는 방법이다. 마지막으로 Texton은 Filter Bank의 각 Filter로 영상과의 Filtering을 통해 생성한 Response를 Feature Vector의 한 요소로 설정하는 방법이다.

Feature Representation
Feature를 표현하는 방법은 여러가지가 있지만, 결국에는 Vector 형태로 표현하게 된다.
이렇게 표현된 Feature Vector를 Plot하면 다음과 같다. 이러한 Feature Vector는 결국 각각의 Class Representation하기에, Feature Vector를 Clustering 해야 한다. 이를 Vector Quantization(Lloyd)라 한다.
앞서 배운 K-meas Clustering과 유사한 방법이지만, "K"를 모르는 상태로 Feature Vector를 Clustering 하면 오른쪽 상단과 같다. 이를 통해 K-means Clustering에서 Center를 계산하는 것과 유사하게, Feature Vector의 평균을 계산하고 이를 각 Class의 Visual Word로 사용한다.
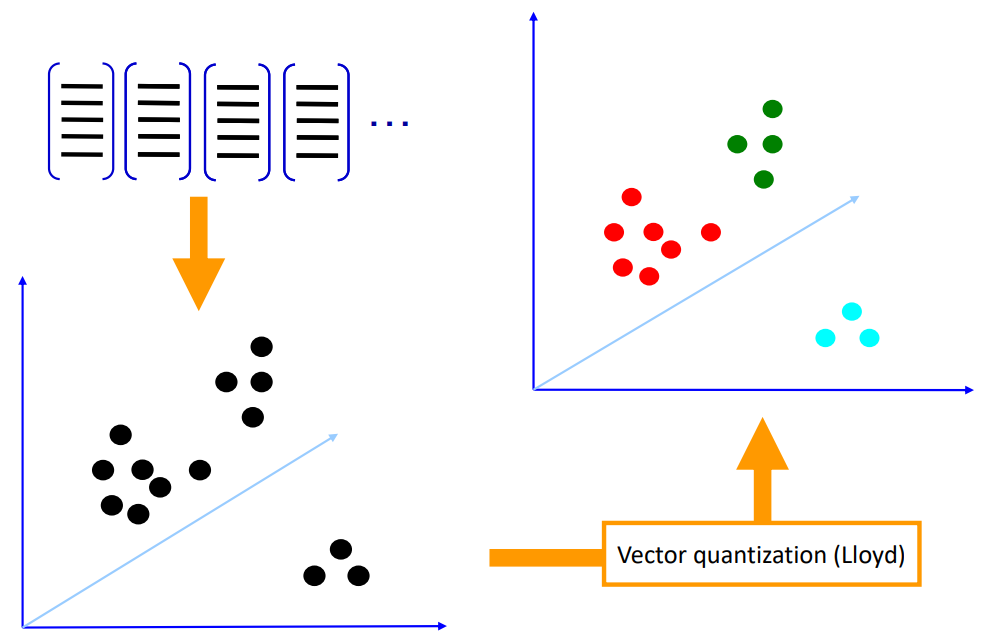
Image Patch를 기반으로 생성한 Codewords(Visual Words)를 살펴보자. 각 Patch 단위로 추출한 Feature들을 Clustering 하여 생성한 Cdoewords이다. 이를 기반으로 영상을 표현하는 방법은 결국, 영상에서 동일한 크기의 Patch를 생성해 Codewords와 유사한 Patches를 찾아 Histogram을 계산하여 영상을 하나의 Vector로 표현한다. 이 Vector는 각 Codeword의 빈도를 요소로 하는 Feature Vector이다.


HoG(Histogram of Oriented Gradient)
또다른 Feature는 HoG 즉, Gradient 방향의 Histogram이 있다. 영상이 달라지면 결국 Gradient의 분포 역시 달라지기에 하나의 Feature가 된다.
(아래 Edge를 Gradient로 해석하는 것이 이해하기 쉽다.)
먼저 모든 Pixel에 대하여 Gradient를 계산한다. 이는 Gradient Orientation & Magnitude를 포함한다. 이후 영상을 8x8 Patch로 나눈뒤, 각 Patch에 대하여 Gradient Magnitude에 가중치를 둔 Gradient Orientation의 Histogram을 계산한다.
아래의 경우 320x240 Resolution을 가지는 영상을 8x8 Patch로 나눴기에, 40x30 bins로 나눠졌으며, 각 bin 안에서 총 9개의 방향에 대해 계산되었다. 이때, 각 방향은 20도를 가지며, Gradient의 부호를 따지지 않기 때문이다. 이를 통해 생성되는 Feature Vector는 30x40x9차원이 되며, 이를 통해 영상을 표현하게 된다.
HoG를 조금 더 살펴보면, 각 bin에 표현된 방향은 9개로 나눈 각 방향을 의미하며, 밝기는 해당 방향으로의 Gradient Magnitude를 의미한다.

HoG를 추출하면 다음과 같다. Flat한 영역은 아무것도 검출되지 않으며, 특정 방향의 Edge는 해당 방향으로 강하게 나타남을 확인할 수 있다. 또한, 눈의 경우 모든 방향으로 Gradient가 검출되기에 방사형으로 표현됨을 확인할 수 있다.

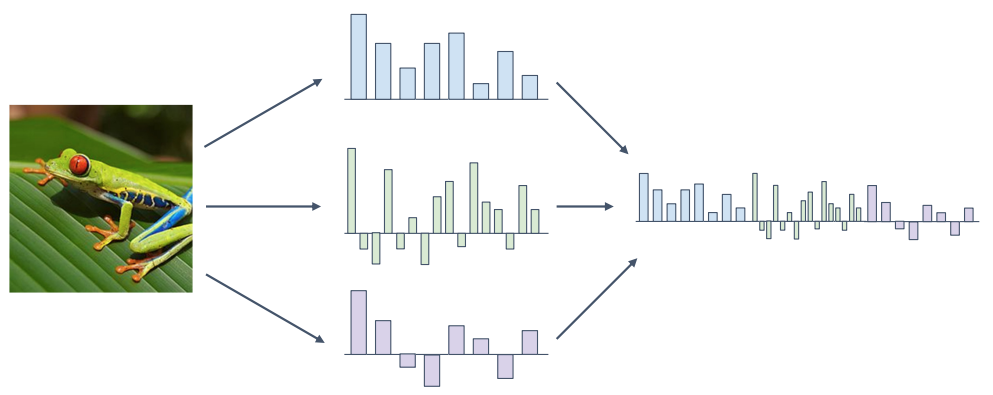
이처럼 영상을 Vector화 하여 표현하는 것을 Feature Transform이라 한다. 또한, 서로 다른 기법으로 취득한 Feature Vector를 Combine 하여 각각의 기법에서의 장점들을 활용하는 것을 Combined Feature라 한다.
'2024 > Study' 카테고리의 다른 글
| [ 컴퓨터 비전 ] Ch5. Deep Learning...7 (0) | 2024.12.07 |
|---|---|
| [ 컴퓨터 비전 ] Ch5. Deep Learning...6 (0) | 2024.12.03 |
| [ 컴퓨터 비전 ] Ch5. Deep Learning...4 (0) | 2024.11.26 |
| [ 컴퓨터 비전 ] Ch5. Deep Learning...3 (0) | 2024.11.26 |
| [ 컴퓨터 비전 ] Ch5. Deep Learning...2 (0) | 2024.11.23 |



