
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- RL
- hm3d
- DP
- r-cnn
- dfs
- Python
- BFS
- YoLO
- GIT
- 딥러닝
- image processing
- deep learning
- opencv
- UC Berkeley
- C++
- NLP
- hm3dsem
- ubuntu
- 강화학습
- Reinforcement Learning
- CNN
- 그래프 이론
- CS285
- 백준
- dynamic programming
- 머신러닝
- LSTM
- machine learning
- MySQL
- AlexNet
- Today
- Total
JINWOOJUNG
[ VLM ] VQA: Visual Question Answering 본문
Papaer
VQA: Visual Question Answering
Introduction
Image&Video Captioning 분야에서의 Computer Vision&Natural Language Processing&Knowledge Representation을 결합한한 연구는 최근들어 많이 진행되고 있다. 기존 Image Captioning Task의 경우 Image의 완벽한 이해 없이도 간단한 Word Statistics만으로도 SOTA 성능을 보이는 것으로 보아 이미지의 깊은 이해 및 추론 성능이 불필요함을 의미한다. 즉, Image Captioning Task가 생각보다 "AI-complete"하지 않음을 시사한다.
Knowledge Representation : 인간의 지식, 정보 등을 기계가 이해하고 사용하도록 구조화해서 표현하는 방법
AI-complete Task : AI의 우수하고 훌룡한 모든 능력이 요구되는 Task
본 논문에서는 "AI-complete" Task를 다음과 같이 정의한다.
- Multi-modal Knowledge가 요구됨
- 정량적인 평가 기준이 명확히 정의되어 연구의 진척 상황을 추적 가능
본 논문에서는 "AI-complete" Task인 VQA: free-form and open-ended Visual Question Answering을 제안한다. VQA는 Image와 그에 관한 자연어 질문을 입력으로 받은 뒤, 자연어 형태의 답변을 출력하는 Task이다.

VQA는 Open-ended Question을 해결하기 위해 다양한 범위의 AI 성능을 요구한다. Image에서 특정 물체의 갯수를 뭇거나(Object Detection), 베지테리안 피자인지 뭇는(Knowledge base Reasoning) 등 vast set of AI capabilities를 요구한다. 또한, 자동적으로 성능을 평가할 수 있는 정량적 평가 기준이 존재한다. "예", "아니오"로 대답할 수 있는 질문들도 존재하고, 질문에 대답으로 요구되는 정답은 특정 단어의 조합으로 표현되기에 정답을 맞힌 질문 수로 성능 평가가 가능하다.
VQA Task Definition
VQA는 2가지 Task가 존재한다.
- Open-ended Answering Task
- 자유로운 형식으로 주관식으로 대답
- Multiple-choice Task
- 사전에 정의된 word list에서 선택
VQA Dataset Definition
VQA는 MS COCO Dataset과 새롭게 생성한 Scene Dataset으로 구성된다. 이때, Scene Dataset은 현실적인 추상 장면 데이터로, 복잡한 시각적 디테일 없이 고차원 추론(상식, 관계, 인과성 등)을 연구하기 위한 목적으로 생성된 데이터 셋 이다. 예를 들어, 가족 식사 장면에서 "이 식사는 채식인가?","이 가족은 저녁을 먹고 있을까?" 등 상황 이해와 논리적 사고가 가능한지 검증하기 위한 Dataset이다.
각 Image에 대하여 3개의 질문이 포함되며, 각 질문에 대해서 10개의 답변은 Confidence Score와 함께 구성된다. 최종적으로, 760K개의 질문과 10M의 대답으로 구성되어 있다.
VQA Dataset에서 사용되는 Open-ended Questions는 실제 현실을 반영하기에 자주 등장하는 질문 종류, 각 질문에 잘 동작하는 Algorithm 등을 파악하기 용이하며, 실제로 매우 다양한 질문이 존재함을 확인할 수 있다. 즉, 기존의 Image Captioning Task와는 확실히 차이나는 구체성, 상식, 추론 능력을 요구하는 복합적 Multi-modal Task이다.
Related Work
VQA Efforts
본 논문 이전에도 VQA에 대한 연구가 존재하였지만, 작은 크기의 Dataset에 대해서 매우 제한된 상황에서 수행되어졌다.
본 논문에서는 사람으로 부터 제공되는 질문과 정답을 사용함으로써, 정답 도출에 요구되는 지식 다양성 및 추론 유형의 다양성이 매우 크다. 이를 통해 모델의 인지 및 추론 성능의 향상을 목표로 한다.
본 눈문에서 제안하는 VQA Task를 위한 Model은 "Late Fusion"을 기반으로 동작한다. LASTM을 이용한 Question Representation과 CNN을 통해 추출한 Image Feature를 Point-wise Multiplication을 통해서 융합한다. 이후 FC Layer를 거치고, Softmax Distribution을 생성하게 된다.

Text-based Q&A
Test 기반의 Q&A Task는 제한된 환경에서 수행된다. 즉, 특정한 상황을 가정한 상태로 진행되기 때문에 실제 현실 반영이 어렵고 표현력이 제한된다.
반면, VQA는 Image를 자연스럽게 Grounding해야 하기에, 질문(Text)과 이미지(Vision)에 대한 이해가 요구된다. 또한, Question은 사람에 의해서 생성되기 때문에 상식적 지식과 복잡한 추론 능력은 필수적이다.
Ground : 자연어 속 단어, 문장을 현실 세계의 개념이나 사각정보와 연결
예를 들어, "개 옆 여자"는 언어적으론 이해할 수 있지만, 누가 "여자"고 "개"가 어디있는지 알 수 없다. 즉, 이미지와 연결(Grounding)을 통해 이미지에 사람과 개가 등장하고, Text와 Image를 Matching시킬 수 있다.
Describing Visual Content
기존 Image Captioning Task는 구체성이 부족하고 비일관적인 경우가 존재한다. 즉, 표면적인 정보만으로 충분히 해결할 수 있는 Not AI-complete Task이다.
반면, VQA는 세부적인 정보를 요구하고, 상식 및 인과 추론능력이 요구되며, 사람처럼 생각해야 해결할 수 있는 Task이다.
Other Vision+Language Tasks
VQA는 질문과 답변에서 매우 풍부하고 다양한 시각적 개념들이 존재하기 때문에, 기존 연구들보다 더욱 심오한 Task이다.
VQA Dataset Collection
Real Images
MS COCO Dataset을 이용한다. MS COCO Image의 경우 다중 객체가 존재하고, 풍부한 Contextual Information을 포함하기에 Visual Complexity가 높다. 따라서 질문과 정답의 다양하성, 포괄성 역시 증가하게 된다.

Abstact Scenes
VQA Task에서는 Low-level Image Processing(Noise, 복잡한 배경 제거 등)이 요구되지 않고, High-level Reasoning을 위한 Data인 Abstract Scenes를 생성한다. 본 논문에서 제안하는 생성 과정은 기존 연구보다 더욱 현실적인 장면 생성이 가능하며, 실제 이미지에 더 가까운 장면을 구성할 수 있다.

Questions
각 Image에 대한 질문은 Low-level Computer Vision Knowledge로도 알 수 있는 색상, 갯수 등의 단순한 질문 뿐만 아니라, Commonsense Knowledge가 요구되는 질문 모두 필요하다. 특히, 질문이 단순히 Commonsense Information 정보 만으로 해결할 수 있는 것이 아닌, Image를 통해 추론할 수 있는 정답이 요구되는 질문으로 구성하였다. 이를 통해 시각적 이해와 상식적 추론의 지속적인 발전을 측정할 수 있다.
아래와 같이 "콧수염이 무엇으로 만들어 졌나요?"라는 질문은 상식만으로 해결할 수 없고, Image에 대한 이해가 필수적으로 요구된다. 이처럼 각 사진에 대해서 3개의 질문을 서로 다른 사람으로 부터 생성하였다.

Answers
질문에 대한 정답은 "예","아니요" 뿐만 아니라, 단답도 가능하며, 동일한 정답에 대한 다양한 표현이 존재하고, 사람마다 서로 다른 견해가 존재한다. 따라서 Discrepancy를 조율하기 위해, 서로 다른 10명의 사람으로 부터 정답을 취득하였으며, 각 정답에 대한 Confidence 즉, "자신의 답변에 대해 얼마나 확신이 있는지"를 "no", "maybe", "yes"로 대답하게 하였고 이는 Confidence Score로써 동작하게 된다.
Testing
- Open-ended Task
Open-ended Task는 아래의 Accuracy 지표를 통해 평가되며, 같은 정답을 최소 3명 이상의 사람이 제공한 경우 100%로 간주하게 된다. 이때, 모든 정답에 대한 간단한 전처리가 수행된 후 비교된다.

- Multiple-choice Task
Multiple-choice Task의 Accuracy 역시 Open-ended Task와 동일한 방법으로 측정되며, 각 질문에 대한 18개의 후보 답변이 사전에 정의된다.
후보 답변의 경우 정답/오답이 무작위로 섞여서 존재하며 생성하는 과정은 다음과 같다.
- Correct
- 10명의 응답자 중 가장 많이 등장한 정답
- Palusible
- 3명이 Image를 보지 않고 유추한 정답
- 상식만으론 답을 할 수 없고, 정답 추론 과정에서 Image에 대한 분석이 필수적으로 요구되도록 하기 위함
- Popular
- 전체 Dataset에 대해서 가장 자주 등장한 상위 10개의 답변
- 답변 선택지만 보고 질문 유형을 유추하는 것을 방지
- Random
- Dataset 내 다른 질문의 정답 중 무작위 선택
Correct, Palusible, Popular의 합집합으로 구성한 뒤 나머지는 Random에서 선택해서 18개의 후보군을 생성하게 된다.

VQA Dataset Analysis
Questions
질문의 처음 4글자를 이용해서 군집화를 한 결과 다음과 같다. 실제 Image와 Abstract Scenes에 대한 질문의 분포가 매우 유사한 것을 확인할 수 있으며, 질문의 다양성이 매우 큼을 확인할 수 있다.
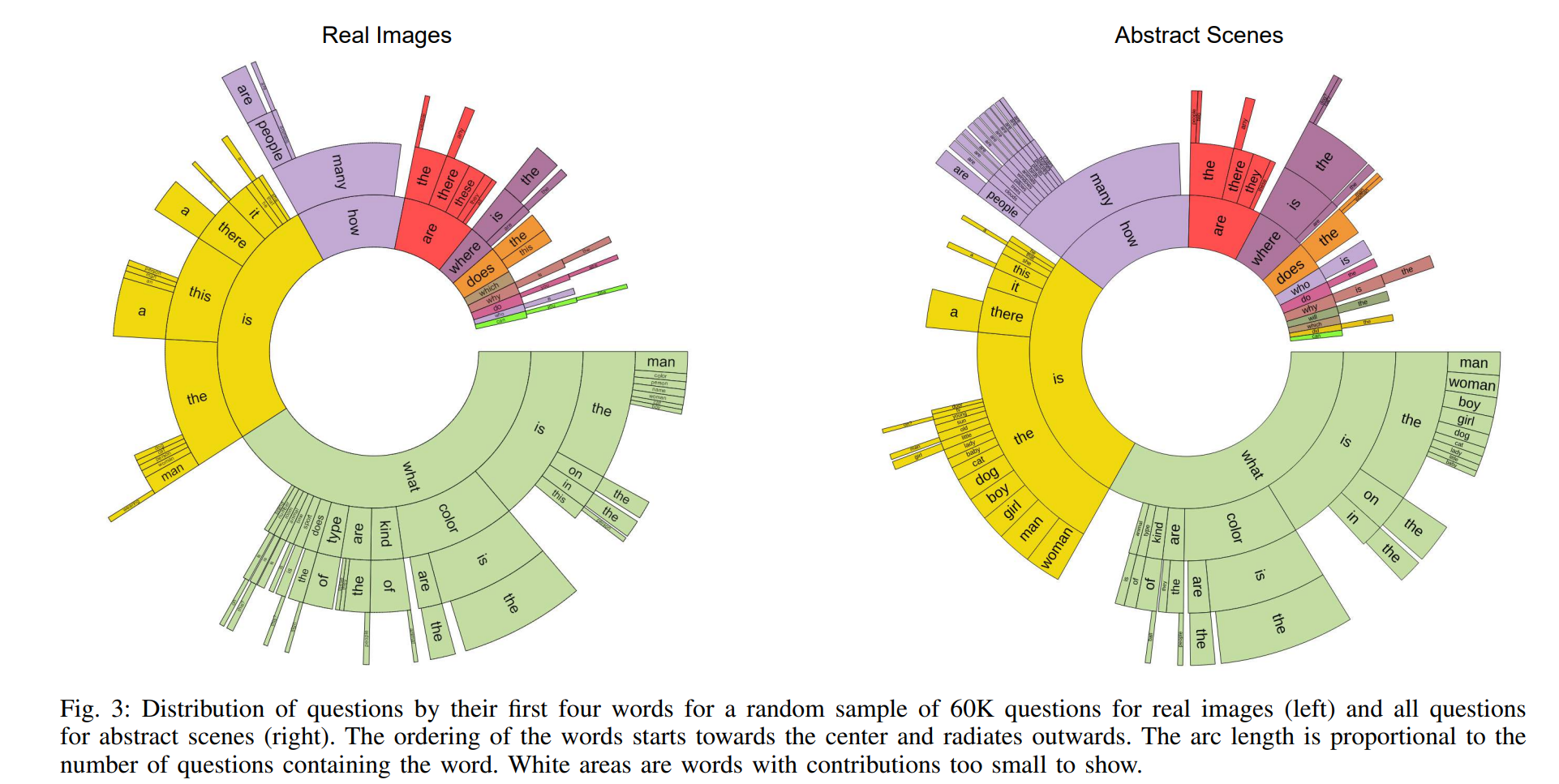
또한 "What is~"에 대한 질문 분포가 매우 많은 것을 확인할 수 있는데, 실제로 "What is~"로 시작하는 질문을 다시 군집화 해 보면 객체의 다양성이 매우 높고, 객체 간의 관계를 물어보는 질문이 분포하는 것을 확인할 수 있다.

Answers
질문에 대한 대답의 경우 "yes","no"나, "What is~" 질문에 대한 다양한 대답, 그리고 "What Color~","Which ~" 등 질문에 대한 구체적인 대답이 존재함을 확인할 수 있다.

기존 Image Captioning Task와 또 다른 점은 대답의 길이가 한 단어로 짧은 경우가 대부분이라는 것이다. 이는 질문이 Image로 부터 구체적인 정보를 요구하도록 유도된 질문이기 때문에 이와 같은 결과가 발생한 것으로 판단된다. 그렇다고 해서 쉬운 Task는 아니다. 앞서 확인한 것 처럼 사람이 제공하는 Open-ended Question으로 부터 취득된 Open-ended Answer이기 때문에 매우 복잡한 추론 과정을 요구하는 Task 이다.
또하나 눈여겨 봐야하는 점은 정답에 대한 편향성이다. 대답이 "Yes", "No"로 나오는 질문은 38.37%, 40.66%(Real Image, Abstract Scene)의 분포를 가지고 있다. 이때, 정답이 "yes"인 경우가 58.83%, 55.86%로, "yes"라고 대답하는 경우 높은 확률로 정답이 되는 것이다. 숫자에 대한 질문의 경우 "2"가 정답인 확률이 26.04%, 39.85%로 편향되어 있음을 확인할 수 있다. 이러한 편향성은 추후 VQA_v2로의 발전으로 이어지게 된다.
VQA Baseline and Methods
Baseline
본 논문에서는 4개의 Baseline을 제공한다.
- random
- VQA Train/Val Dataset에서 상위 1,000개의 정답 중 무작위 선택
- prior ("yes")
- Open-ended, Multiple-choice Task에서 모두 "yes" 선택
- per Q-type prior
- Open-ended Task에서는 질문 유형마다 가장 자주 등장한 정답 선택
- Multiple-choice Task에서는 Open-ended에서 선택한 정답과 가장 유사한 답변을 후보군에서 선택
- nearest neighbor
- Test Image-Question Set에 대해, Train Dataset에서 가장 가까운 K개의 Image-Question Set 선정
- Open-ended Task에서는 해당 Nearest Image-Question Set 중 가장 자주 등장한 GT Answer 선택
- Multiple-choice Task에서는 Open-ended에서 선택한 정답과 가장 유사한 답변을 후보군에서 선택
- Train Dataset에서 Test Dataset과 가장 유사한 Image-Question의 정답을 활용
Methods
본 논문에서는 VQA를 위한 Vision Language Model을 제안하였으며, 최종적으로 K개의 Softmax Output을 통해 정답을 예측하게 된다. 이때, K는 Train/Val Dataset의 최빈 정답 1,000개로 설정되며, Train/Val Dataset GT의 82.67%를 차지한다.
논문에서는 다양한 Methods를 설명하지만, 가장 성능이 좋은 deeper LSTM Q + norm I에 대해서만 본 포스팅에서 다룰 것이다.
- Image Channel
norm I는 Image를 VGGNet의 마지막 Hidden Layer의 Activations를 $L_2$ Normalization을 거친 4096 차원으로 Embedding 한다. 이후 FC Layer+tanh를 통과시켜 1024 차원이 된다.
- Question Channel
deeper LSTM Q는 Question을2개의 Hidden Layer를 가진 LSTM을 사용해서 2048 차원으로 Embedding 한다. 각 Hidden Layer의 마지막 Cell State, Hidden State를 모두 결합하면 각각 512 차원이므로 2048 차원이 되고, 이후 FC Layer+tanh를 통과시켜 1024 차원으로 변환하게 된다.
이때, Question은 Tokenization을 거쳐 300 차원의 Vector가 되고, FC Layer+tanh를 통과시킨 후 LSTM의 Input이 된다.
- Multi-Layer Perceptron
각 Multi-modal을 Late Fusion하기 위해 Point-wise Multiplication을 수행한다. 이후 2개의 Hidden Layer로 구성된 MLP에 입력되며, 각 Hidden Layer는 1,000개의 유닛을 가지며, Dropout(p=0.5), tanh를 거친다. 최종적으로 Softmax를 통과하게 되면 K개의 정답 분포 중 가장 높은 것으로 정답을 예측하게 된다.
모델 전체는 Cross-entropy Loss를 통해 E2E 학습되며, VGGNet의 경우 ImageNet Classification Task에 사용된 Pre-trained Parameter를 그데로 사용한다.
Results
결과는 다음과 같다. Image만 사용한 I의 경우 prior ("yes")보다 낮음을 확인할 수 있다. 하지만, Language만 활용한 BoW Q, LSTM Q의 경우 성능이 생각보다 높고, nearest neighbor과 유사한 성능이라고 확인할 수 있는데, 이는 앞서 살펴본 정답의 편향성을 Language Model이 효과적으로 사용하기 때문이다.
본 논문에서 제안한 deeper LSTM Q + norm I의 경우 월등한 성능을 보이지만, 실제 사람의 수준에 한참 미치지 못하는 수준이다.
