
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- deep learning
- Python
- Reinforcement Learning
- image processing
- BFS
- UC Berkeley
- 딥러닝
- C++
- 머신러닝
- r-cnn
- opencv
- AlexNet
- CNN
- CS285
- 그래프 이론
- 강화학습
- hm3d
- ubuntu
- machine learning
- DP
- MySQL
- RL
- 백준
- NLP
- YoLO
- LSTM
- hm3dsem
- dfs
- dynamic programming
- GIT
- Today
- Total
JINWOOJUNG
[ Transformer to LLaMA ] ELMo: Embeddings from Language Models 본문
[ Transformer to LLaMA ] ELMo: Embeddings from Language Models
Jinu_01 2025. 4. 28. 20:24본 포스팅은 서울대학교 강필성 교수님의 Transformer to LLaMA 강의자료 및 강의를 기반으로
공부한 내용을 정리하는 포스팅입니다.
https://www.youtube.com/watch?v=zV8kIUwH32M&list=PLRmOKHpXQgr8CDy-eG4pC1hSNkkneCaWJ
Embeddings from Language Models
ELMo는 2018년에 제안된 새로운 Word Embedding Method이다. Embeddings from Language Models의 약자인 ELMo는 이름에서도 알 수 있듯이 Pre-trained Language Model을 사용한다. 즉, Pre-trained Language Model을 기반으로, 문맥에 따라 단어의 Embedding이 달라지는 Contextualized Word Embedding을 제공하는 방법이다.
그렇다면 어떠한 Word Representation이 우수하다고 할 수 있을까?
먼저, 단어의 복잡한 특징을 모델링 해야 한다. 예를 들어, 구문(문법)적으로, 의미적으로 해당 단어가 나타내는 것을 알고 있어야 한다. 또한, 문맥상에서 다양하게 사용되는 방식을 담고 있어야 한다. 예를 들어, 다의어인 "눈"을 살펴보자. 사람의 "눈"과 하늘에서 내리는 "눈"은 서로 다른 의미를 가지지만 하나의 단어로 표현된다. 따라서 우수한 Word Embedding은 이를 서로 다르게 Embedding 해야 한다.

기존 Word Embedding 연구인 GloVe와 달리 ELMo의 구조인 biLM은 다이어를 문맥에 따라 서로 다른게 Embedding 가능한 것을 확인할 수 있다. GloVe의 "play"는 Sports 분야에 편향되어 있지만, biLM 구조의 경우 Sports 에서의 "Play"와 연극에서의 "Play"가 서로 다르게 Embedding 되어 문맥에 따라 구분됨을 확인할 수 있다.
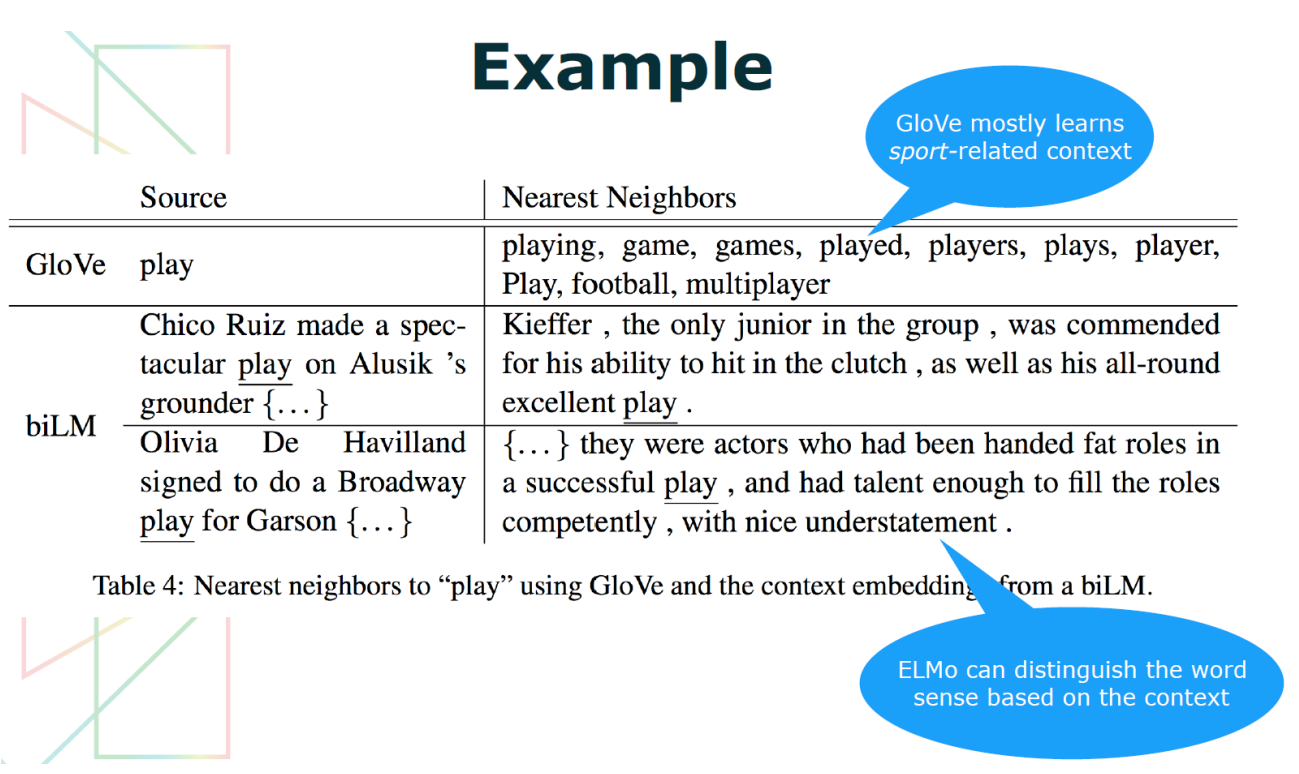
ELMo 특징
- 개별 Word Embedding은 모든 Input Sequence Information을 사용해서 결정됨
예를 들어, 기존 연구는 "improvisation"을 Embedding 한다고 하면, 해당 단어만 고려해서 Embedding을 진행하였다. 하지만, ELMo는 "Let's stick to improvisation in this skit" Input Sequence를 모두 고려해서 "improvisation" Word Embedding을 진행하게 된다. 따라서 단어의 의미를 문맥(Context)에 맞게 정확하게 Embedding 할 수 있으며, 다의어를 잘 구분할 수 있다.

- biLM(bi-directional LSTM)
ELMo는 현재까지 주어진 Sequence 다음에 등장할 단어를 예측하는 고전적인 Language Model 방식으로 학습된다. 즉, $P(W_t | W_{t-1}, W_{t-2}, W_{t-3})$를 통해 다음 단어를 예측하게 되는 것이다.

하지만, 기존의 순방향 LSTM과 달리, ELMo는 순방향과 역방향의 언어 모델을 모두 학습하는 bi-directional LSTM 구조이다. 이를 통해 앞서 등장한 단어 뿐만 아니라 이후에 등장하는 단어들을 고려하여 특정 단어의 Embedding을 구할 수 있다. 이때, 아래 그림에서의 "Embedding"은 Character-level CNN을 사용해서 단어를 문자(Character) 단위로 처리해서 만든 Embedding이다. 이를 Input으로 하여 LSTM을 태워서 최종적으로 ELMo가 구해지게 된다.
Character-level Embedding을 하는 이유는, OOV(Out-of-Vocabulary, 모르는 단어)를 줄이기 위함이다. 기존 연구인 Word2Vec, GloVe와 달리, 형태소 정보를 더욱 반영해서 접미사가 달라지는 것도 반영할 수 있기 때문이다(play, playing, player).

bi-LSTM의 정보들을 이용해 ELMo Embedding을 만드는 방법은 다음과 같다.
- 먼저 Forward LM, Backward LM의 동일한 Layer의 Hidden Vectors, Embedding을 Concatenate 한다.
- Concatenated Vectors에 대해서 Downstream Task에 따른 Weight를 곱해준다.
- Weighted Concatenated Vectors를 모두 더해서 최종적인 ELMo Embedding을 생성한다.
이 과정에서 Downstream Task에 따른 Weight Vectors는 Downstream Task에 따라 학습되는 Parameter이다.

ELMo는 bi-directional LSTM을 이용한 Language Model을 학습하여, 문맥을 반영한 Word Representation을 생성하는 방법이다. ELMo는 biLM구조를 기반으로 하며, Downstream Task와 무관하게 대규모 Corpus만 주어지면 미리 사전 학습(pre-training)할 수 있다. ELMo는 Task-specific Representation을 제공하기 때문에,
- Weight Vector $s_k^{task}$ 는 Downstream Task에 따라 학습되어, 각 Layer의 Output을 가중합(weighted sum)하는 역할을 한다.
- Scale Parameter $r^{task}$ 는 Weighted ELMo Embedding 전체를 다시 조정(scale)하는 학습 가능한 스칼라 값이다.
이 구조 덕분에, 하나의 ELMo 모델로 다양한 Task에 맞게 유연하게 Feature를 조정하여 사용할 수 있다.
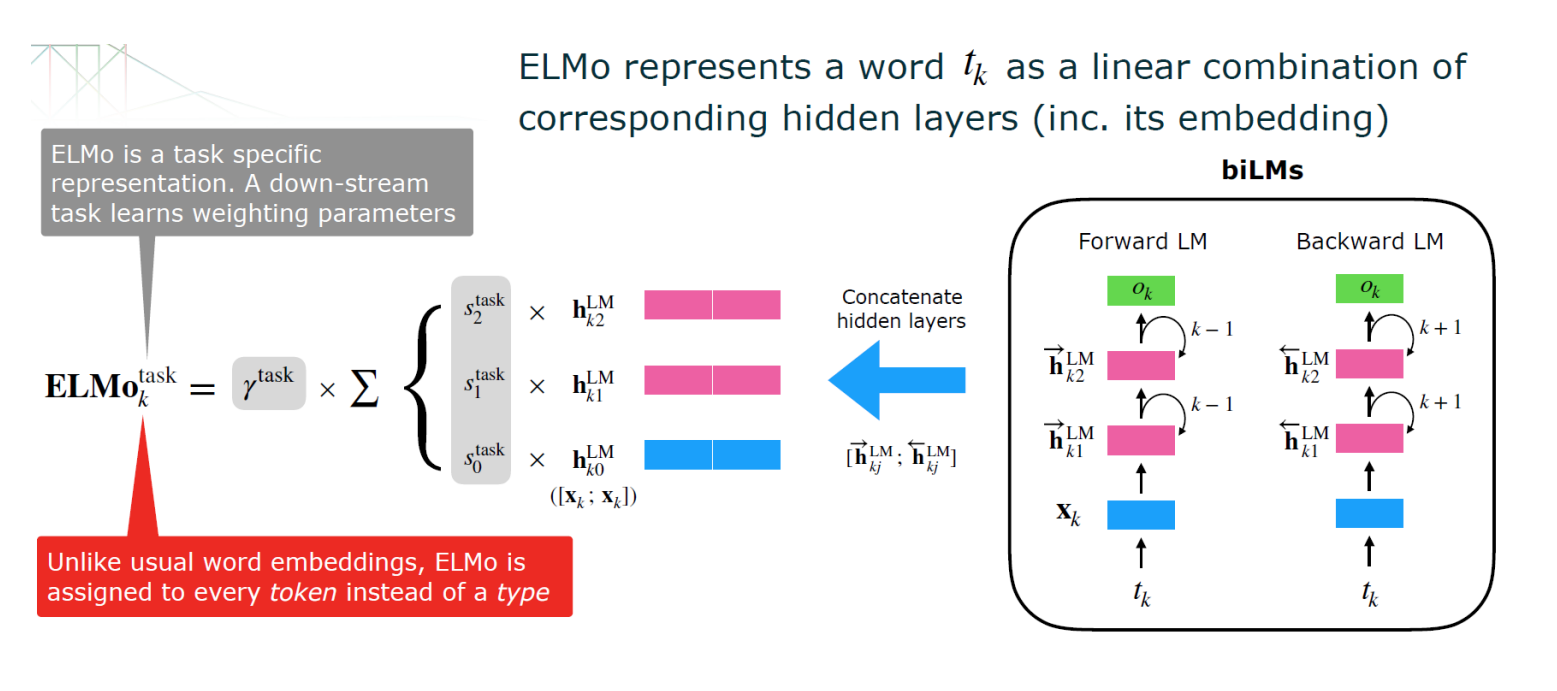
앞서 설명한 일련의 과정을 수식적으로 다시 살펴보자.
$N$개의 Token으로 구성된 Sequence $(t_1, t_2, \cdots,t_N)$이 주어졌을 때, Forward LM은 과거 시점의 정보 $(t_1, t_2, \cdots,t_{k-1})$를 이용해서 $t_k$에 대한 확률을 모델링한다. 즉, Forward LM이 모델링하는 전체 Sequence의 확률은 아래와 같이 정의할 수 있다.
$$p(t_1, t_2, \cdots, t_N) = \prod_{k=1}^{N}(t_k|t_1, t_2, \cdots, t_{k-1})$$
앞서 설명한 것 처럼, 각 Token(Word) Embedding은 문맥에 상관없이 Pre-trained 된 Token Embedding 혹은 CNN 기반으로 계산된다. 이를 Input으로 하여, $k$ 위치에 대해서 각 LSTM Layer의 Output은 Contex-dependent representation $\vec{h}_{k,j}^{LM}$으로 표현된다. 이때, $j$는 LSTM Layer의 층수를 의미한다.
Backward LM은 그와 반대 방향으로, 이후에 나오는 Token들을 이용하게 된다.$$p(t_1, t_2, \cdots, t_N) = \prod_{k=1}^{N}(t_k|t_{k+1}, t_{k+2}, \cdots, k_N)$$
따라서 최종적으로 ELMo의 Parameters는 Jointly maximizes the log likelihood of the forward and backward direction을 목적으로 한다.

이를 각 Downstream Task에 적용하는 것을 고려하면, Task-specific한 파라미터인 $r^{task}$와 $s_j^{task}$를 추가하여 최종 ELMo Representation을 다음과 같이 표현할 수 있다.

Experiment
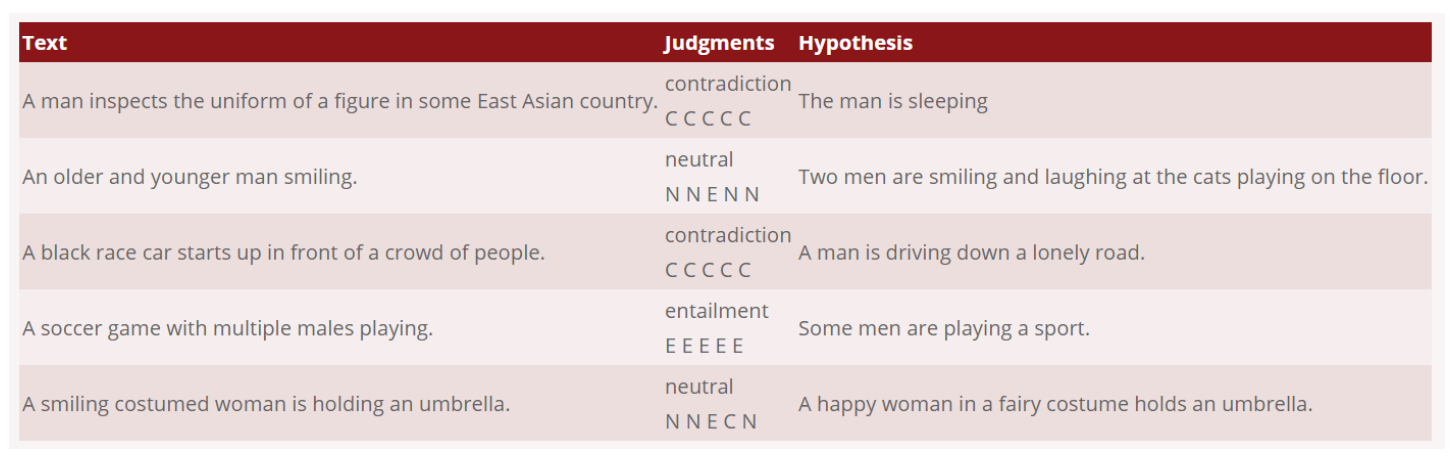
ELMo를 평가하기 위해 Natural Language Inference(NLI) Task에 적용해서 평가하였다. 해당 Task는 Hypothesis가 Text에 대해서 Entailment(True), Contradiction(False), Neutral(중립)인지 관계를 분류하는 Task이다.
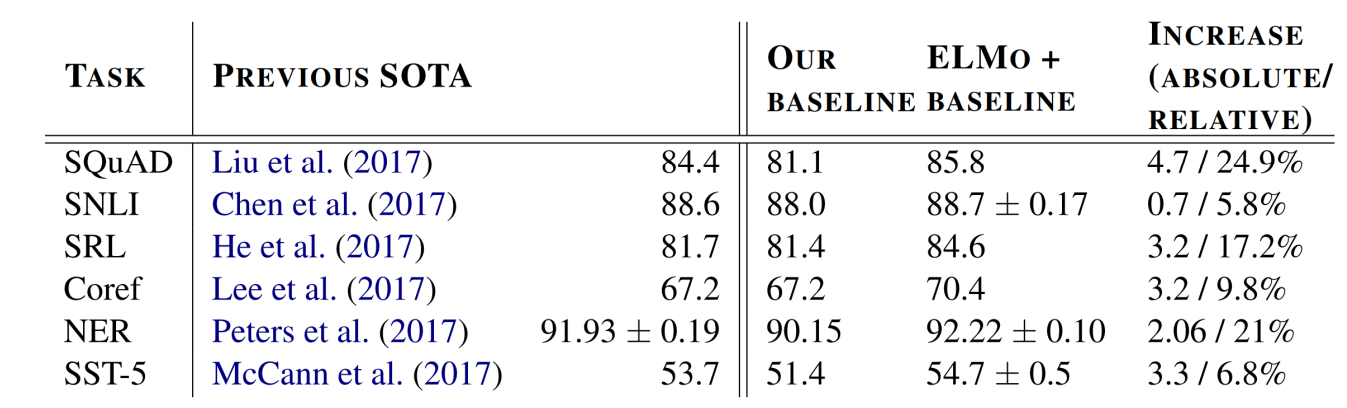
Baseline Model과 ELMo를 사용했을 때의 성능은 다음과 같다. 성능이 증가했다도 중요하지만, ELMo는 다양한 Downstream Task에서 성능을 향상시킬 수 있음이 더욱 중요하다고 생각한다.
그렇다면, ELMo Embedding을 각 Downstream Task에서 어떻게 사용하는 것이 좋을까?
가장 성능이 좋은 방법은 대규모 Unsupervised Language Modeling 즉, Corpus만 주어졌을 때 Pre-train 이후, Downstream Task의 Input Embedding에 Concatenate 시킨 뒤, 해당 Model의 Hidden Layers의 Output에도 ELMo Embedding을 추가시키는 방법이 가장 효과적이었다.

또한, 앞서 언급한 Weight를 부여하는 방법 역시 Task-specific 하게 Layer에 따라 서로 다른 가중치를 부여하는 것이 가장 효과적이라고 한다. 이는 각 Layer에 따라서 학습되는 목적이 다르기 때문인데, 상위 Layer에서는 문맥과 관련된 추상적인 의미가 학습되고, 하위 Layer에서는 문법적인 특징과 관련된 의미가 학습된다. 따라서 Task에 따라 각 Layer의 Hidden Vector에 대한 가중치를 조절해서 다양한 Downstream Task에 효과적으로 적용시킬 수 있다.

이처럼 biLM의 모든 내부 Layers의 정보를 활용하기에 ELMo는 Deep Respresentation이며, 특정 단어에 쌓인 Embedding을 선형결합 하는 위 방법이 단순히 LSTM의 마지막 Layer에 대한 정보만 활용하는 것 보다 더 효과적이다.
Reference
https://jalammar.github.io/illustrated-bert/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 2021 Update: I created this brief and highly accessibl
jalammar.github.io
Deep contextualized word representations(ELMo)
'NLP, LLM, Multi-modal' 카테고리의 다른 글
| Habitat-Matterport 3D semantic dataset (0) | 2025.06.25 |
|---|---|
| SoundSpaces 2.0: A Simulation Platform for Visual-Acoustic Learning (0) | 2025.06.22 |
| [ Transformer to LLaMA ] Transformer..02 (0) | 2025.04.25 |
| [ NLP ] BLEU Score: 기계번역 평가지표 (0) | 2025.04.25 |
| [ Transformer to LLaMA ] Transformer..01 (0) | 2025.04.25 |


