
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- dynamic programming
- LSTM
- 강화학습
- YoLO
- RL
- UC Berkeley
- CNN
- machine learning
- MySQL
- GIT
- ubuntu
- AlexNet
- r-cnn
- 딥러닝
- opencv
- DP
- dfs
- hm3dsem
- deep learning
- C++
- CS285
- NLP
- 백준
- image processing
- 그래프 이론
- Python
- 머신러닝
- hm3d
- BFS
- Reinforcement Learning
- Today
- Total
JINWOOJUNG
Linear Regression 본문
본 게시글은 인하대학교 유상조 교수님의 Machine Learning Tutorial Seminar
수강 후정리를 위한 포스팅입니다.
모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다.
Classification(분류) : 구별되는 클래스를 예측하는 작업
Regression(회귀) : 실수값/연속적인 값(continuous qunatity)을 예측하는 작업
Linear Regression
Linear Regression은 하나 혹은 다수의 Input(explanatory/independent variables)와 Output(a scalar response/dependent variable)의 상관관계를 모델링하는 것이다.
이때 Input Data는 다음과 같이 정의된다.
$$x^i = [{x_1}^i, {x_2}^i,\cdots, {x_p}^i]$$
i 번째 data인 $x^i$는 p dimension을 가지는 data(feature)로 정의된다.
만약 10x10 Image data가 존재한다고 하면 각각의 pixel을 데이터로 가지기 때문에, 해당 데이터는 10x10 dimension data가 된다.
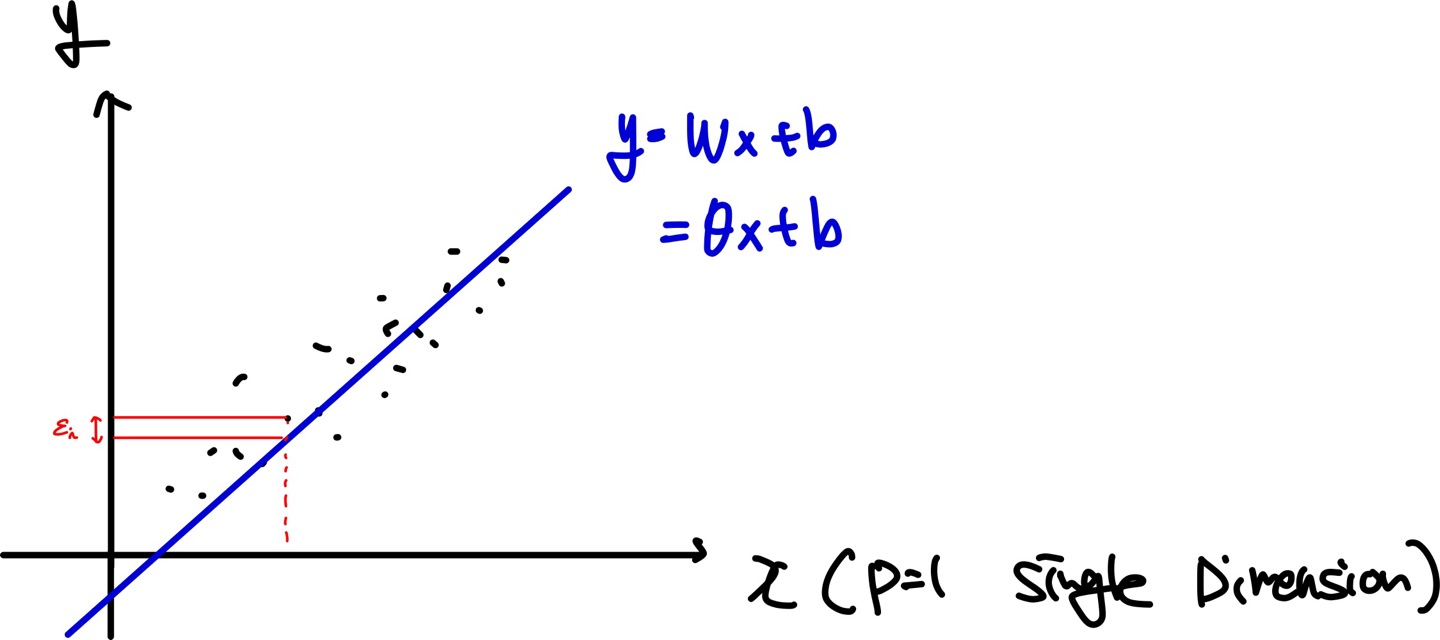
만약 dimension이 1인 data가 여러개 있다고 가정하면 위 그래프 처럼 찍을 수 있고, 이를 만족하는 model을 정의하는 것이 linear regression이다.
이때, $y_i$는 i번째 dependent variable, $x_{ij}$는 p dimension을 가지는 i번째 data, $\theta_j$는 parameter vector, $\varepsilon_i$는 i번째 error라고 가정하면 아래와 같이 표현할 수 있다. 이때, $\theta_0$는 bias parameter이다.
$$y_i = \theta_0 + \theta_1x_{i1}+\cdots+ \theta_px_{ip}+\varepsilon_i /qquad (i = 1,\cdots,n)$$
$$Y=X\theta + \varepsilon$$
Matrix로 표현 시 각 data에 가장 앞 부분을 1로 설정하고, $\theta$ vector에 $\theta_0$를 추가하여 편향을 표현한다.
위 예시와 같이 데이터 분포 시 1차식으로 표현 가능하다. 하지만 아래와 같이 데이터가 분포한다면 1차식 만으로 표현시 큰 Error가 발생할 것이다.

따라서 우리는 polynomial expression(다항식)이 필요하고 따라서 모델링을 다음과 같이 다항식으로 할 수 있다.
$$h_i = \theta_0 + \theta_1t_i + \theta_2{t_2}^2 + \cdots + \theta_p{t_i}^p + \varepsilon_i$$
하지만 다항식 표현은 $t$에 대해서 선형적이지 않다. 하지만 관점을 달리하면 즉, $\theta$에 대하여 표현한다면, 선형식으로 해석된다.
즉, $x_i$를 $(1,x_{i1},\cdots,x_{ip})$가 아닌 $(1,t_i,{t_i}^2,\cdots,{t_i}^p)$로 표현한다면 $\theta$에 대한 선형모델을 만들 수 있다.
$$h_i = x_i\theta + \varepsilon_i$$
위 예를 $x_1 = 30, x_2 = 60, x_3 = 70,\cdots$라고 가정하자(p=2).
위 식에 의해 값이 아닌 time value가 input data로 들어가기 때문에 $x_1 = (1,1,1), x_2 = (1,2,4), x_3 = (1,3,9)$가 된다.
따라서 이를 Matrix로 표현하면,
$$ \begin{bmatrix}
30\\
60\\
70
\end{bmatrix} = \begin{bmatrix}
1 &1 &1 \\
1 &2 &4 \\
1 &3 &9 \\
\end{bmatrix} \begin{bmatrix}
\theta_0\\
\theta_1 \\
\theta_2
\end{bmatrix} $$
Linear하게 표현되므로 Inverse Matrix를 이용해 계산하면,$\theta$ 즉, Weight 값을 구할 수 있다.
Least Square Estimator
Linear Regression 식을 다시 써 보면 $$y = X\theta + \varepsilon$$으로 나타낼 수 있다.
따라서 최적의 $\theta$ 즉, 최적의 weight를 구하는 방법은 Error를 최소화하는 것이다. 즉, $\varepsilon = Error = y - X\theta$이고, Positive/Negative 상관없이 Error를 최소화 하는 것이 목적이므로 절댓값을 씌어 표현할 수 있다.
$$\left\| y-X\hat{\theta}\right\| = \underset{\theta}{min} \left\| y-X\theta\right\|$$
여기서 $ \hat{\theta}$은 추정치를 의미한다.
$L_2 norm$의 경우 Outlier에 대한 Error를 극대화 하기 위해서 위 식에서 제곱을 한다. 따라서 최적의 $\theta$를 찾는 Task는 $ \underset{\theta}{min} \left\| y-X\theta\right\|^2$를 푸는 Task로 이어지고, 최소의 경우 극값이기에 미분이 0이 되는 지점을 계산하여 찾아주면 아래와 같다.
$$ \underset{\theta}{min} \left\| y-X\theta\right\|^2 \qquad \to \qquad (-2)X^T(y-X \hat{\theta}) = 0$$
$\theta$에 대하여 풀기 위해 식을 단순화 하면
$$X^TX \hat{\theta} = X^Ty$$이므로 least squre의 solution은 $$ \hat{\theta} = (X^TX)^{-1}X^Ty$$를 계산함으로써 unique solution을 얻을 수 있다. 이때, $X$가 Full Rank여야 Inverse가 존재하며, Matrix 연산의 경우 Dimension이 클수록 복잡성이 커지는 경향이 있다.
Gradient Descent Algorithm
따라서 Weight를 Iterative하게 구하기 위해서 새로운 접근 방법이 대두되었다.
Linear Hypothesis를 $H_W(X) = WX+b$라고 정의하는데, 여기서 $b$는 위에서 정의한 $Bias(\theta_0)$와 같다.

우리의 목표는 최적의 $W$를 찾는 것이기 때문에, 빨간색으로 표시된 Error를 최소화 해야 하는 것이 목표이다. 따라서 Cost Function을 위에서 살펴본 $L_2$ Loss Function으로 정의하면 아래와 같다.
$$ cost = \frac{1}{m}\sum_{i=1}^{m}[H(X^{(i)})-t ^{(i)}]^2$$
이를 Linear Hypothesis으로 표현하면 아래와 같다.
$$ cost(W,b) = \frac{1}{m}\sum_{i=1}^{m} [WX^{(i)}-t^{(i)}]^2 $$
따라서 학습의 목표는 최적의 파라미터 W,b를 찾는 문제로 귀결된다.
$$(W^*, b^*) = \underset{W,b}{min} \ cost(w,b)$$
cost를 minimize하기 위해 식을 아래와 같이 약간 변형하여 미분했을 때 분모를 간단하게 취해보자
$$ cost(W,b) = \frac{1}{2m}\sum_{i=1}^{m}[ WX^{(i)}+b-t ^{(i)}]^2$$
이때, 다음과 같이 bias를 Matrix에 함께 표현하고
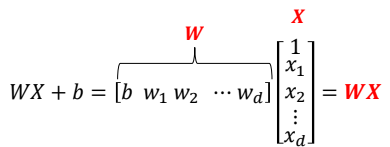
Weight를 다음과 같이 표현할 수 있다.

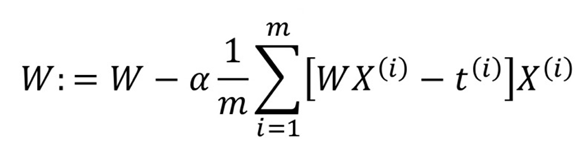
즉, Cost가 최소가 되기 위해서는 극소점을 찾아야 하므로 미분했을 때 값이 0이 되는 방향으로 변화해야 한다. 따라서 미분 식 앞에 -를 붙임으로써 기울기가 음수이면 커지고 양수이면 작아지는 방향으로 학습될 수 있도록 표현 가능하다.
이때, $\alpha$는 learning rate로 hyperparameter이다.
따라서 learning rate를 너무 작게 설정하면 변화량이 너무 작고, 너무 크면 0이 수렴할 수 없게 된다.
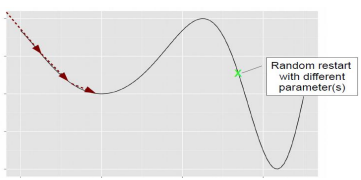
또한, 아래와 같이 global minima가 아닌 locat minima에 수렴하는 경우도 발생하기에 Initial에 영향을 받는다.
'Machine Learning' 카테고리의 다른 글
| [ ML & DL 1] Introduction to Supervised Learning (0) | 2024.11.22 |
|---|---|
| Long Short Term Memory(LSTM) (1) | 2024.01.13 |
| Recurrent Neural Network(RNN) (2) | 2024.01.13 |


