
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- machine learning
- 강화학습
- AlexNet
- hm3dsem
- Python
- C++
- dynamic programming
- UC Berkeley
- ubuntu
- DP
- 백준
- deep learning
- dfs
- CS285
- r-cnn
- RL
- Reinforcement Learning
- 딥러닝
- LSTM
- GIT
- MySQL
- BFS
- opencv
- 그래프 이론
- NLP
- hm3d
- 머신러닝
- YoLO
- CNN
- image processing
- Today
- Total
JINWOOJUNG
[ 영상 처리 ] Part5. OpenCV K-Means Clustering & Segmentation(C++) 본문
RGB 색 공간을 HSV로 확장시키고, 특정 객체의 색을 추출하고 Segmentation을 진행한다. 이를 K-Means Clustering으로 확장시켜 동일한 색상을 가진 객체를 Clustering 한 뒤, Segmentation을 진행하여 결과를 비교한다.
Before This Episode
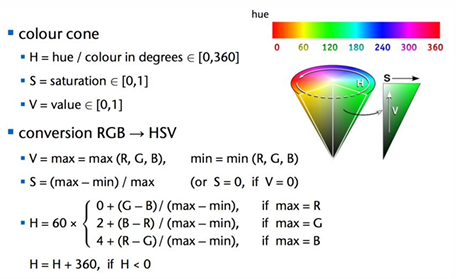
영상을 표현하는데 있어서 다양한 색상 모델이 존재한다.
Gray Model
밝기 정보만으로 영상을 표현. 0(검정)~255(흰)으로 $2^8$가지의 Intensity로 Pixel Intensity를 표현.
RGB Model
기본적인 색상모델로, 하나의 색을 Red, Green, Blue 3가지 성분의 조합으로 표현.
HSV Model
Hue(색조), Saturation(채도), Value(명도) 3가지 성분으로 색상을 표현.
H(색조)가 색상 자체를 결정하고 0~179의 범위를 가짐.
S(채도)는 다른 색이 섞이지 않는 순수한 색일수록 더 높은 값을 가지며 0~255의 범위를 가진다. 0일수록 탁해져 무채색인 회색에 가까우며, 255면 가장 선명한(순수한) 색을 의미한다.
V(명도)는 밝고 어두운 정도를 나타내며 0~255의 범위를 가진다. 작을수록 어둡다.
RGB에서 HSV 색 공간으로의 변환은 아래 공식을 따른다.
이미지에서 색상 정보 추출

다음과 같은 이미지가 주어졌다고 하자. 우리는 노란색을 가지는 바나나라고 알 수 있으나, 이를 코드적으로 구현해야 한다. RGB 색 공간을 사용하여 색상을 추출하는 것도 하나의 방법이지만, 같은 노란색이라 해도 서로 다른 밝기를 가진다. 따라서 HSV 색 공간으로 옮겨 색상을 추출하는 것이 더욱 효과적이다.
MyBGR2HSV()
Mat MyBGR2HSV(Mat src_img) {
double b, g, r, h, s, v;
Mat dst_img(src_img.size(), src_img.type());
for (int y = 0; y < src_img.rows; y++) {
for (int x = 0; x < src_img.cols; x++) {
b = (double)src_img.at<Vec3b>(y, x)[0];
g = (double)src_img.at<Vec3b>(y, x)[1];
r = (double)src_img.at<Vec3b>(y, x)[2];
// Max, min 값 구하기
double MAX = max(max(b, g), r);
double MIN = min(min(b, g), r);
// BGR2HSV
v = MAX;
s = v == 0 ? 0 : (MAX - MIN) / MAX; // v가 0이면 s는 0임
s *= 255; // s의 범위를 0~255까지 맞춰줌(uchar)
if (MAX == MIN) { // MAX - MIN이 0일 때 예외처리
h = 0;
}
else if (MAX == r) {
h = 60 * ((g - b) / (MAX - MIN));
}
else if (MAX == g) {
h = 60 * (2 + (b - r) / (MAX - MIN));
}
else {
h = 60 * (4 + (r - g) / (MAX - MIN));
}
// 오버플로우 처리
h = h < 0 ? h + 360 : h;
// 변환된 색상 대입
// double 자료형의 값을 본래 자료형으로 변환
dst_img.at<Vec3b>(y, x)[0] = (uchar)h;
dst_img.at<Vec3b>(y, x)[1] = (uchar)s;
dst_img.at<Vec3b>(y, x)[2] = (uchar)v;
}
}
return dst_img;
}
MyBGR2HSV()는 cvtColor(src_img, dst_img, COLOR_BGR2HSV); 와 동일한 기능을 하는 이미지를 BGR -> HSV 색 공간으로 변환시키는 함수이다. 모든 픽셀에 접근하여 Mat::at()을 통해 각 픽셀의 BGR Value를 가져온다. 이후 앞서 소개한 BGR2HSV 변환 공식에 근거하여 HSV Value를 구한다. 이후 Mat::at()을 통해 변환된 이미지의 픽셀에 HSV 값을 각 체널에 맞게 할당한다. 결국 반환되는 dst_img는 원본 이미지를 HSV 색 공간으로 변환한 이미지가 된다.


실행결과 OpenCV의 cvtColor의 결과와 동일함을 알 수 있다.
HSV 색 공간에서 특정 객체의 색을 추출하기 위해선 각 색이 HSV에서 어떤 Range를 갖는지 알아야 한다.
vector<pair<int, int>> st_Parameter = {
{0, 15}, // Red
{155, 179}, // Red
{15, 30}, // Orange
{30, 45}, // Yellow
{45, 90}, // Green
{90, 135}, // Blue
{135, 155} // Purple
};
vector, pair를 활용하여 각 색상을 나타내는 H Value의 Min, Max Range를 표현하였다. 각 색상의 순수한 정도와 밝고 어두운 정도를 S,V Value가 나타낸다. 이때, S Value가 너무 낮으면 색이 무채색으로 표현되어 색을 구별할 수 없고, V Value가 너무 낮으면 색이 검정색이 되어 색상을 구별할 수 없다. 따라서 S,V Value는 모두 50~255의 Range를 갖는 Value만 유효한 Value로 측정 하였다.
Mat MakeColorMask(const Mat& st_HSVImage) {
double f64_H, f64_S, f64_V, Min_S = 50, Max_S = 255, Min_V = 50, Max_V = 255;
int y, x, s32_I;
string Color;
Mat arst_Mask[2], st_ResultMask;
// vector<pair<string, int>>를 사용하여 각 색상의 이름과 초기 카운트 값 설정
vector<pair<string, int>> st_Color = {
{"Red", 0},
{"Orange", 0},
{"Yellow", 0},
{"Green", 0},
{"Blue", 0},
{"Purple", 0}
};
// 픽셀 데이터 순회 및 빈도 계산
for (y = 0; y < st_HSVImage.rows; y++) {
for (x = 0; x < st_HSVImage.cols; x++) {
// OpenCV에서는 Hue 값이 0~179 범위
f64_H = st_HSVImage.at<Vec3b>(y, x)[0];
f64_S = st_HSVImage.at<Vec3b>(y, x)[1];
f64_V = st_HSVImage.at<Vec3b>(y, x)[2];
// 채도 및 명도 범위 필터링
if (f64_S < Min_S || f64_S > Max_S || f64_V < Min_V || f64_V > Max_V) {
continue;
}
// Hue 값에 따른 색상 분류
if ((f64_H >= st_Parameter[0].first && f64_H <= st_Parameter[0].second) || (f64_H >= st_Parameter[1].first && f64_H <= st_Parameter[1].second)) {
st_Color[0].second += 1; // Red
}
else if (f64_H >= st_Parameter[2].first && f64_H <= st_Parameter[2].second) {
st_Color[1].second += 1; // Orange
}
else if (f64_H >= st_Parameter[3].first && f64_H <= st_Parameter[3].second) {
st_Color[2].second += 1; // Yellow
}
else if (f64_H >= st_Parameter[4].first && f64_H <= st_Parameter[4].second) {
st_Color[3].second += 1; // Green
}
else if (f64_H >= st_Parameter[5].first && f64_H <= st_Parameter[5].second) {
st_Color[4].second += 1; // Blue
}
else if (f64_H >= st_Parameter[6].first && f64_H <= st_Parameter[6].second) {
st_Color[5].second += 1; // Purple
}
}
}
// 빈도 값을 기준으로 내림차순 정렬
sort(st_Color.begin(), st_Color.end(), compareFrequency);
// 정렬된 색상 빈도 출력
for (s32_I = 0;s32_I<2;s32_I++)
{
Color = st_Color[s32_I].first;
if (Color == "Red")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[0].first, Min_S, Min_V), cv::Scalar(st_Parameter[0].second, Max_S, Max_V));
Mat st_TmpMask = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[1].first, Min_S, Min_V), cv::Scalar(st_Parameter[1].second, Max_S, Max_V));
cv::add(arst_Mask[s32_I], st_TmpMask, arst_Mask[s32_I]);
}
else if (Color == "Orange")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[2].first, Min_S, Min_V), cv::Scalar(st_Parameter[2].second, Max_S, Max_V));
}
else if (Color == "Yellow")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[3].first, Min_S, Min_V), cv::Scalar(st_Parameter[3].second, Max_S, Max_V));
}
else if (Color == "Green")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[4].first, Min_S, Min_V), cv::Scalar(st_Parameter[4].second, Max_S, Max_V));
}
else if (Color == "Blue")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[5].first, Min_S, Min_V), cv::Scalar(st_Parameter[5].second, Max_S, Max_V));
}
else if (Color == "Purple")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[6].first, Min_S, Min_V), cv::Scalar(st_Parameter[6].second, Max_S, Max_V));
}
cout << "Sorted Color: " << Color << endl;
}
cv::add(arst_Mask[0], arst_Mask[1], st_ResultMask);
return st_ResultMask;
}
// 비교 함수: 두 색상 간의 빈도수를 기준으로 내림차순 정렬
bool compareFrequency(const pair<string, int>& a, const pair<string, int>& b) {
return a.second > b.second;
}
MakeColorMask()는 HSV 영상에서 각 픽셀이 속하는 색상을 Count하고, 해당 색상에 속하는 Pixel만 Filtering 할 수 있는 Mask를 반환하는 함수이다.
double f64_H, f64_S, f64_V, Min_S = 50, Max_S = 255, Min_V = 50, Max_V = 255;
int y, x, s32_I;
string Color;
Mat arst_Mask[2], st_ResultMask;
// vector<pair<string, int>>를 사용하여 각 색상의 이름과 초기 카운트 값 설정
vector<pair<string, int>> st_Color = {
{"Red", 0},
{"Orange", 0},
{"Yellow", 0},
{"Green", 0},
{"Blue", 0},
{"Purple", 0}
};
// 픽셀 데이터 순회 및 빈도 계산
for (y = 0; y < st_HSVImage.rows; y++) {
for (x = 0; x < st_HSVImage.cols; x++) {
// OpenCV에서는 Hue 값이 0~179 범위
f64_H = st_HSVImage.at<Vec3b>(y, x)[0];
f64_S = st_HSVImage.at<Vec3b>(y, x)[1];
f64_V = st_HSVImage.at<Vec3b>(y, x)[2];
// 채도 및 명도 범위 필터링
if (f64_S < Min_S || f64_S > Max_S || f64_V < Min_V || f64_V > Max_V) {
continue;
}
// Hue 값에 따른 색상 분류
if ((f64_H >= st_Parameter[0].first && f64_H <= st_Parameter[0].second) || (f64_H >= st_Parameter[1].first && f64_H <= st_Parameter[1].second)) {
st_Color[0].second += 1; // Red
}
else if (f64_H >= st_Parameter[2].first && f64_H <= st_Parameter[2].second) {
st_Color[1].second += 1; // Orange
}
else if (f64_H >= st_Parameter[3].first && f64_H <= st_Parameter[3].second) {
st_Color[2].second += 1; // Yellow
}
else if (f64_H >= st_Parameter[4].first && f64_H <= st_Parameter[4].second) {
st_Color[3].second += 1; // Green
}
else if (f64_H >= st_Parameter[5].first && f64_H <= st_Parameter[5].second) {
st_Color[4].second += 1; // Blue
}
else if (f64_H >= st_Parameter[6].first && f64_H <= st_Parameter[6].second) {
st_Color[5].second += 1; // Purple
}
}
}
먼저 Min, Max S,V Value는 50과 255으로 설정하였다. 또한, 객체가 하나의 색으로만 표현될 수 없기 때문에, 가장 높은 빈도를 가지는 2가지 색상에 대하여 Segmentation을 진행하기 위해 Mask를 배열로 설정하였다. st_Color Vector는 영상의 모든 픽셀을 돌면서 해당 픽셀의 HSV Value가 속하는 색상을 찾아서, 해당 색상을 Count 하기 위한 Vector이다.
이중 for문을 통해 영상의 모든 픽셀에 접근하여 Mat::at()을 이용해 해당 픽셀의 HSV Value를 가져온다. 이후 각 픽셀이 어느 색상의 HSV Value Range에 속하는지 판단하고, 해당 색상의 Count를 증가시킨다.
// 빈도 값을 기준으로 내림차순 정렬
sort(st_Color.begin(), st_Color.end(), compareFrequency);
// 정렬된 색상 빈도 출력
for (s32_I = 0;s32_I<2;s32_I++)
{
Color = st_Color[s32_I].first;
if (Color == "Red")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[0].first, Min_S, Min_V), cv::Scalar(st_Parameter[0].second, Max_S, Max_V));
Mat st_TmpMask = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[1].first, Min_S, Min_V), cv::Scalar(st_Parameter[1].second, Max_S, Max_V));
cv::add(arst_Mask[s32_I], st_TmpMask, arst_Mask[s32_I]);
}
else if (Color == "Orange")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[2].first, Min_S, Min_V), cv::Scalar(st_Parameter[2].second, Max_S, Max_V));
}
else if (Color == "Yellow")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[3].first, Min_S, Min_V), cv::Scalar(st_Parameter[3].second, Max_S, Max_V));
}
else if (Color == "Green")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[4].first, Min_S, Min_V), cv::Scalar(st_Parameter[4].second, Max_S, Max_V));
}
else if (Color == "Blue")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[5].first, Min_S, Min_V), cv::Scalar(st_Parameter[5].second, Max_S, Max_V));
}
else if (Color == "Purple")
{
arst_Mask[s32_I] = MyInRange(st_HSVImage, cv::Scalar(st_Parameter[6].first, Min_S, Min_V), cv::Scalar(st_Parameter[6].second, Max_S, Max_V));
}
cout << "Sorted Color: " << Color << endl;
}
cv::add(arst_Mask[0], arst_Mask[1], st_ResultMask);
return st_ResultMask;
이후 st_Color를 빈도 값을 기준으로 내림차순 정렬시킨다. 정렬된 색상 빈도를 기준으로 첫번째, 두번째로 많이 존재하는 색상을 가지는 픽셀에 대하여 Mask를 생성한다. 이후 생성된 두 Mask를 cv::add()를 통해 더해 줌으로써 첫번째, 두번째로 많이 존재하는 색상을 가지는 픽셀들만 Filtering(255를 가짐)하는 Mask를 반환한다.
MyInRange()
Mat MyInRange(Mat st_HSVImage, Scalar st_Min, Scalar st_Max) {
Mat st_Mask = Mat::zeros(st_HSVImage.size(), CV_8UC3); // 검정색 Mask 생성
// HSV Min Value
double H_Min = st_Min[0];
double S_Min = st_Min[1];
double V_Min = st_Min[2];
// HSV Max Value
double H_Max = st_Max[0];
double S_Max = st_Max[1];
double V_Max = st_Max[2];
double f64_H, f64_S, f64_V;
int x, y;
for (y = 0; y < st_HSVImage.rows; y++) {
for (x = 0; x < st_HSVImage.cols; x++) {
// 해당 픽셀의 HSV Value를 가져옴
f64_H = st_HSVImage.at<Vec3b>(y, x)[0];
f64_S = st_HSVImage.at<Vec3b>(y, x)[1];
f64_V = st_HSVImage.at<Vec3b>(y, x)[2];
// 해당 픽셀의 HSV가 Min, Max 범위 내에 존재하면 Mask를 흰색으로 설정 -> 추후 필터링
if (f64_H >= H_Min && f64_H <= H_Max && f64_S >= S_Min && f64_S <= S_Max && f64_V >= V_Min && f64_V <= V_Max)
{
st_Mask.at<Vec3b>(y, x)[0] = 255;
st_Mask.at<Vec3b>(y, x)[1] = 255;
st_Mask.at<Vec3b>(y, x)[2] = 255;
}
}
}
return st_Mask;
}
MyInRange()는 인자로 HSV Image, Min, Max HSV Value Range를 가진다. 해당 함수는 HSV Image에서 특정한 색상을 가지는 픽셀을 검출하고, Mask에서 해당 위치만 255로 설정하여 해당 Mask를 반환하는 함수이다. 함수가 호출될 때 이미 검출한 색상은 정해져 있고, 해당 색상의 Min, Max HSV Value Range가 인자로 넘어온다. 따라서 먼저 모두 검은색(0)인 Mask를 생성하고, 받아온 Min, Max Value를 각 변수에 저장한다. 이후 영상의 모든 픽셀에 접근하여, 해당 픽셀의 HSV Value를 가져온 뒤, 해당 Min Max Value Range에 속하면, Mask의 해당 픽셀 좌표의 Value를 모두 255로 설정한다.
결국 위 함수는 특정 색상 영역에 속하는 픽셀만 255 Value를 가지는 Mask를 반환하는 함수이다.

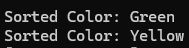
실행결과 가장 빈도수가 높은 두 색상은 초록색과 노랑색이고, 해당 색상을 가지는 Pixel Position만 255로 할당된 Mask가 생성됨을 확인할 수 있다.
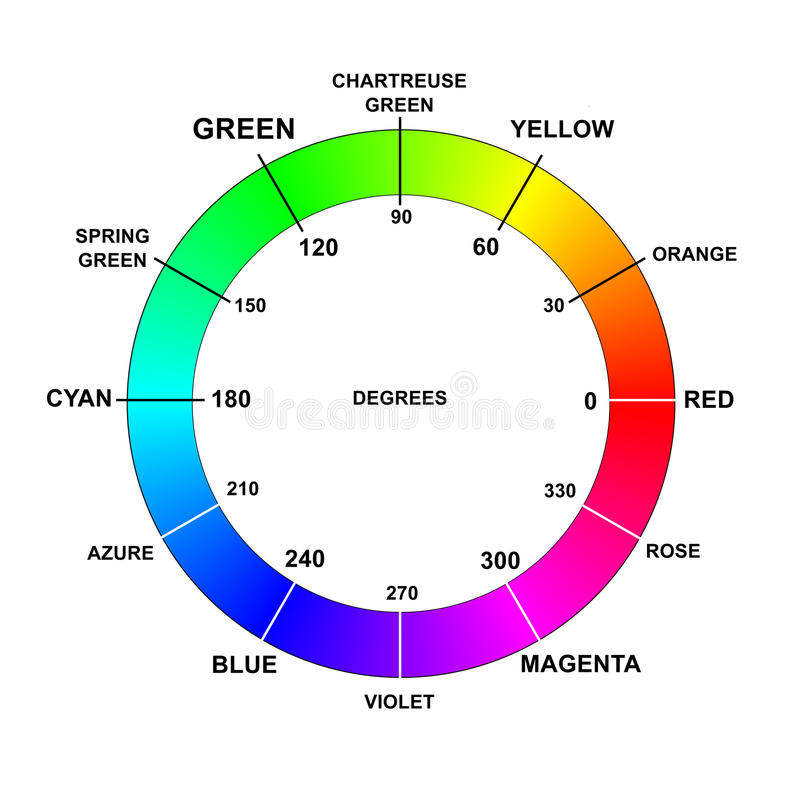

실제 HSV 색 공간에서 H Value Range에 따른 색상은 왼쪽과 같다. 360은 8Bits로 표현되지 못하기 때문에 OpenCV에서는 0~179 Range로 표현되며, 그에 따른 색상 분류는 오른쪽과 같이 정의했기 때문에, Green이 가장 많다고 나타났다.
main()
int main()
{
// 1. Clustering
Mat st_OriginalImage = imread("banana.jpg", 1);
Mat st_HSVImage, st_Mask, st_ResultImage, st_Final;
st_HSVImage = MyBGR2HSV(st_OriginalImage);
st_Mask = MakeColorMask(st_HSVImage);
bitwise_and(st_OriginalImage, st_Mask, st_ResultImage);
hconcat(st_OriginalImage, st_Mask, st_Final);
hconcat(st_Final, st_ResultImage, st_Final);
imshow("st_Final", st_Final);
//---------------------------------------------------------
}
생성된 st_Mask를 원본 이미지와 bitwise_and 연산을 통하여 255로 설정된 픽셀만 Filtering 한 결과 아래와 같이 이미지에서 과일에 해당하는 영역만 정확히 추출됨을 확인할 수 있다.

K-Means Clustering Using OpenCV
K-Means Algorithm은 데이터를 k개의 영역(Cluster)로 나누는 군집화(Clustering) Algorithm이다. 비지도 학습 중 하나로, 무작위 데이터에 대하여 임의의 기준으로 군집화 하는 알고리즘이다.
- 임의의 k개의 중심 설정
- 초기 중심점에 따른 서로 다른 결과
- 모든 데이터에 대하여 가장 가까운 중심을 선택하여 해당 Cluster에 포함
- 각 Cluster에 대하여 중심점을 다시 계산
- 중심이 변경되면 2~3 과정을 반복
- 설정된 조건(Max Iteration, Threshold etc)에 따라서 알고리즘 종료
일반적으론 위와 같은 Process로 동작한다.
kmeans(samples, k, labels,
TermCriteria(TermCriteria::MAX_ITER | TermCriteria::EPS, 10000, 0.0001),
attemps, KMEANS_PP_CENTERS, centers);
cv::kmeans()는 다양한 Parameter를 가지는데, samples는 Data, k는 Cluster 개수, labels는 Clustering 이후 각 픽셀 위치에 따른 Label이 저장되며, TermCriteria는 종료 조건, attemps는 서로 다른 초기 중심점에 따른 시행 횟수, KMEANS_PP_CENTERS는 초기 중심점 선정 Flag 중 하나, centers는 각 Cluster의 Center Intensity Value를 의미한다.
// K-Means Using OpenCV
Mat CvKmeans(Mat src_img, int k) {
//2차원 영상 -> 1차원 벡터
Mat samples(src_img.rows * src_img.cols, src_img.channels(), CV_32F);
// 3 Channel일 경우 3개의 1차원 벡터에 대하여 각 Pixel Position에 Intensity 할당
for (int y = 0; y < src_img.rows; y++) {
for (int x = 0; x < src_img.cols; x++) {
if (src_img.channels() == 3) {
for (int z = 0; z < src_img.channels(); z++) {
samples.at<float>(y + x * src_img.rows, z) = (float)src_img.at<Vec3b>(y, x)[z];
}
}
else {
samples.at<float>(y + x + src_img.rows) = (float)src_img.at<uchar>(y, x);
}
}
}
//opencv k-means 수행
Mat labels;
Mat centers;
int attemps = 5;
// 군집의 평균 색 저장
vector<pair<int,int>> MeanColor;
pair<int, int> zeroPair(0, 0);
MeanColor = vector<pair<int, int>>(k, zeroPair); // Cluster 개수만큼 초기화
Mat st_HSVImage;
cvtColor(src_img, st_HSVImage, COLOR_BGR2HSV); // Cluster의 평균 색을 추출하기 위해 HSV Image 변환
//1차원 벡터 => 2차원 영상
Mat dst_hsvimg(src_img.size(), src_img.type());
Mat dst_img(src_img.size(), src_img.type());
// k개의 Cluster로 Clustering 수행
// 지정된 최대 반복 횟수인 10000번을 반복하거나 Cluster의 중심 변화가 0.0001 이하로 줄어들면 더 이상 변화가 없다고 판단하고 Kmeans() 종료
// KMEANS_PP_CENTERS는 초기 중심점 설정 Flag 중 하나로, 임의로 선정된 첫번째 Cluster 중심에 대하여, 해당 중심점과의 거리의 제곱에 비례하는 다음 중심점 선택
kmeans(samples, k, labels,
TermCriteria(TermCriteria::MAX_ITER | TermCriteria::EPS, 10000, 0.0001),
attemps, KMEANS_PP_CENTERS, centers);
// 군집의 평균 색 추출
for (int y = 0; y < st_HSVImage.rows; y++) {
for (int x = 0; x < st_HSVImage.cols; x++) {
// labels에는 각 Pixel Position에 따른 Label이 존재
int cluster_idx = labels.at<int>(y + x * st_HSVImage.rows, 0);
MeanColor[cluster_idx].first += st_HSVImage.at<Vec3b>(y, x)[0]; // 해당 Cluster에 속하는 픽셀의 H Value를 따로 저장
MeanColor[cluster_idx].second += 1; // 각 Cluster의 개수를 Count
}
}
// 각 Cluster의 H Value를 Cluster의 속하는 픽셀 개수로 나눠 줌으로써 평균 색 결정
for (int i = 0; i < k; i++)
{
MeanColor[i].first /= MeanColor[i].second;
}
// 다시 2차원 영상으로 변경
for (int y = 0; y < src_img.rows; y++) {
for (int x = 0; x < src_img.cols; x++) {
// labels에는 각 Pixel Position에 따른 Label이 존재
int cluster_idx = labels.at<int>(y + x * src_img.rows, 0);
for (int z = 0; z < src_img.channels(); z++) {
if (z == 0)
{
// 해당 Cluster의 속하는 픽셀은 Cluster의 평균 색으로 할당
dst_img.at<Vec3b>(y, x)[z] =
(uchar)MeanColor[cluster_idx].first;
}
else
{
// 채도, 명도는 Cluster Center Value 할당
dst_img.at<Vec3b>(y, x)[z] =
(uchar)centers.at<float>(cluster_idx, z);
}
}
}
}
return dst_img;
}
CvKmeans()를 Cluster의 평균 색으로 Segmentation을 수행하기 위해 변형하였다. 하나하나 살펴보자.
//2차원 영상 -> 1차원 벡터
Mat samples(src_img.rows * src_img.cols, src_img.channels(), CV_32F);
// 3 Channel일 경우 3개의 1차원 벡터에 대하여 각 Pixel Position에 Intensity 할당
for (int y = 0; y < src_img.rows; y++) {
for (int x = 0; x < src_img.cols; x++) {
if (src_img.channels() == 3) {
for (int z = 0; z < src_img.channels(); z++) {
samples.at<float>(y + x * src_img.rows, z) = (float)src_img.at<Vec3b>(y, x)[z];
}
}
else {
samples.at<float>(y + x + src_img.rows) = (float)src_img.at<uchar>(y, x);
}
}
}
먼저 cv::kmeans()의 인자로 들어가는 1차원 벡터 영상 데이터를 생성해야 한다. 모든 픽셀에 접근하여 만약 영상이 3체널일 경우 3개의 1차원 벡터에 각 픽셀의 Intensity를 할당한다. 이때 1차원 벡터에 저장해야 하기 때문에 Mat::at()의 좌표는 (y+x*src_img.rows, z)임을 유의하자. 만약 Grayscale 영상이면, 그냥 1개의 1차원 벡터에 할당하면 된다.
//opencv k-means 수행
Mat labels;
Mat centers;
int attemps = 5;
// 군집의 평균 색 저장
vector<pair<int,int>> MeanColor;
pair<int, int> zeroPair(0, 0);
MeanColor = vector<pair<int, int>>(k, zeroPair); // Cluster 개수만큼 초기화
Mat st_HSVImage;
cvtColor(src_img, st_HSVImage, COLOR_BGR2HSV); // Cluster의 평균 색을 추출하기 위해 HSV Image 변환
//1차원 벡터 => 2차원 영상
Mat dst_hsvimg(src_img.size(), src_img.type());
Mat dst_img(src_img.size(), src_img.type());
// k개의 Cluster로 Clustering 수행
// 지정된 최대 반복 횟수인 10000번을 반복하거나 Cluster의 중심 변화가 0.0001 이하로 줄어들면 더 이상 변화가 없다고 판단하고 Kmeans() 종료
// KMEANS_PP_CENTERS는 초기 중심점 설정 Flag 중 하나로, 임의로 선정된 첫번째 Cluster 중심에 대하여, 해당 중심점과의 거리의 제곱에 비례하는 다음 중심점 선택
kmeans(samples, k, labels,
TermCriteria(TermCriteria::MAX_ITER | TermCriteria::EPS, 10000, 0.0001),
attemps, KMEANS_PP_CENTERS, centers);
cv::kmeans의 각 파라미터에 대한 설명은 위해서 하였으므로 생략한다. Clustering Algorithm이 종료되면, labels에는 각 Position이 속하는 Cluster가 저장되며, centers에는 각 Cluster의 중심 픽셀 Intensity가 저장된다.
Clustering 이후 Cluster를 평균 색으로 Segmentation 하기 위하여 MeanColor를 선언하였다. 또한, 평균 색을 결정하기 위하여 src_img를 HSV 색 공간으로 변형하여 st_HSVImage에 저장하였고, cv::cvtColor()를 사용하였다.
// 군집의 평균 색 추출
for (int y = 0; y < st_HSVImage.rows; y++) {
for (int x = 0; x < st_HSVImage.cols; x++) {
// labels에는 각 Pixel Position에 따른 Label이 존재
int cluster_idx = labels.at<int>(y + x * st_HSVImage.rows, 0);
MeanColor[cluster_idx].first += st_HSVImage.at<Vec3b>(y, x)[0]; // 해당 Cluster에 속하는 픽셀의 H Value를 따로 저장
MeanColor[cluster_idx].second += 1; // 각 Cluster의 개수를 Count
}
}
// 각 Cluster의 H Value를 Cluster의 속하는 픽셀 개수로 나눠 줌으로써 평균 색 결정
for (int i = 0; i < k; i++)
{
MeanColor[i].first /= MeanColor[i].second;
}
군집의 평균 색을 추출하기 위하여 전체 픽셀에 접근하여 해당 픽셀의 Cluster Lable을 cluster_idx에 할당하고, st_HSVImage에서 해당 픽셀의 H Value를 MeanColor Vector의 해당 Cluster 공간에 더하고, Cluster 개수를 증가시킨다.
따라서 MeanColor[i].first에는 각 Cluster에 해당하는 픽셀의 H Value 합이 들어있고, MeanColor[i].second에는 각 Cluster에 속하는 픽셀 개수가 들어있다. 따라서 각 Cluster의 H Value를 Cluster의 속하는 픽셀 개수로 나눠 줌으로써 평균 색 결정한다.
// 다시 2차원 영상으로 변경
for (int y = 0; y < src_img.rows; y++) {
for (int x = 0; x < src_img.cols; x++) {
// labels에는 각 Pixel Position에 따른 Label이 존재
int cluster_idx = labels.at<int>(y + x * src_img.rows, 0);
for (int z = 0; z < src_img.channels(); z++) {
if (z == 0)
{
// 해당 Cluster의 속하는 픽셀은 Cluster의 평균 색으로 할당
dst_img.at<Vec3b>(y, x)[z] =
(uchar)MeanColor[cluster_idx].first;
}
else
{
// 채도, 명도는 Cluster Center Value 할당
dst_img.at<Vec3b>(y, x)[z] =
(uchar)centers.at<float>(cluster_idx, z);
}
}
}
}
return dst_img;
영상을 다시 2차원 영상으로 되돌리기 위해서 1차원 벡터에 접근한다. cluster_idx는 해당 픽셀이 속하는 cluster의 label이 할당된다. 따라서 centers에 저장된 각 label에 따른 Intensity 정보를 가져와 dst_img에 저장하면 우리가 아는 영상으로 되돌릴 수 있다. 이때, H Value는 계산한 Cluster의 평균 값을 사용하고, S,V Value는 Cluster Center Value로 유지함으로써 Cluster의 평균 색으로 Segmentation 하였다.


Clustering Num인 k는 Cluster 개수를 결정하는 Parameter이다. k=3으로 수행한 경우 오른쪽과 같이 이미지가 3가지 색상으로 단순화되어 구분이 분명한 큰 영역을 형성하는 것을 확인할 수 있다. 하지만 "해"그림이 사라지고, "산"이랑 "흙"이 같은 Cluster로 군집화 되는 등 색상의 표현력이 비교적 떨어지는 것을 확인할 수 있다.


k를 5로 증가시키면 "흙"과 "산"이 서로 다른 Cluster로 구분되며, 7로 증가시키면 사라졌던 "해"도 서로 다른 Cluster로 군집화 되는 것을 확인할 수 있습니다. 즉, 세부적인 부분이 명확히 표현되며, 색상의 표현력이 증가함을 확인할 수 있습니다.


Original Image K-Means Cluster Result(k=100)
k를 100으로 하여 Cluster 개수를 많이 늘리면 원본과 유사한 결과를 얻을 수 있다. 하지만, 각 Cluster의 크기가 작아지고 Overfitting이 발생하여 영상에 Noise가 낀 것처럼 보일 수 있다. 따라서 적절한 값을 찾는 것이 중요하다.
My K-Means Clustering
OpenCV를 사용하지 않고 직접 K-Means Clustering을 구현 해 보자.
MyKMeans
Mat MyKMeans(Mat src_img, int n_cluster) {
vector<Scalar>clustersCenters;
vector<vector<Point>>ptInClusters;
double threshold = 0.001;
double oldCenter = INFINITY;
double newCenter = 0;
double diffChange = oldCenter - newCenter;
createClustersInfo(src_img, n_cluster, clustersCenters, ptInClusters);
while (diffChange > threshold) {
newCenter = 0;
for (int k = 0; k < n_cluster; k++) { ptInClusters[k].clear(); }
findAssociatedCluster(src_img, n_cluster, clustersCenters, ptInClusters);
diffChange = adjustClusterCenters(src_img, n_cluster, clustersCenters, ptInClusters, oldCenter, newCenter);
}
Mat dst_img = applyFinalClusterTolmage(src_img, n_cluster, ptInClusters, clustersCenters);
return dst_img;
}
Vector clustersCenters는 각 Cluster의 Centor Points의 Intensity를 저장한 Vector로, cv::Scalar객체에 Intensity 정보를 저장한다. Vector ptlnClusters는 각 Cluster에 속하는 Pixel 들의 Position 정보를 저장한 Vector로, 각 Cluster에 대하여 vector<Point>로 속하는 Pixel Position 정보를 저장한다. threshold는 Clustering Algorithm을 중단할 Threshold이고, threshold 보다 중심의 변화량이 적으면 Clustering Algorithm을 중단한다. oldCenter, newCenter는 Cluster 중심의 변화량의 평균값을 나타냄으로써 이전 변화량과 현재 변화량의 Difference를 구한 뒤, diffChange를 계산하여 Clustering Algorithm의 진행 여부를 결정하게 된다.
createClustersInfo()
void createClustersInfo(Mat imgInput, int n_cluster, vector<Scalar>& clustersCenters,
vector<vector<Point>>& ptInClusters) {
// Random Number Generator Initialization
RNG random(cv::getTickCount());
for (int k = 0; k < n_cluster; k++) {
// Cluster의 Random Centor Point 설정
Point centerKPoint;
centerKPoint.x = random.uniform(0, imgInput.cols);
centerKPoint.y = random.uniform(0, imgInput.rows);
// 해당 픽셀의 색상 값을 가져옴
Scalar centerPixel = imgInput.at<Vec3b>(centerKPoint.y, centerKPoint.x);
// B,G,R 각각의 Value를 centerK에 저장
Scalar centerK(centerPixel.val[0], centerPixel.val[1], centerPixel.val[2]);
clustersCenters.push_back(centerK); // Cluster의 중심 픽셀의 Intensity 정보를 저장
vector<Point>ptInClustersK;
ptInClusters.push_back(ptInClustersK); // 해당 Cluster에 속하는 Points를 추후 저장할 vector<Point> 객체
}
}
createClustersInfo()는 초기 Cluster Center를 결정하는 함수이다. Random Number Generator를 사용하여 Cluster 개수인 k번 만큼 반복하여 초기 centerPoint를 결정한다. 이후 해당 픽셀의 Intensity를 centerPixel에 저장하고, 각 체널의 Intensity를 centerK Scalar 객체에 저장하여, 이를 clustersCenters Vector에 저장한다. 이후 해당 Cluster에 속하는 Points를 추후에 저장할 vector<Point> ptlnClustersK를 ptlnClusters Vector에 저장한다.
이를 통하여 Random 하게 선택된 k개의 Cluster Center와, Center의 Intensity, Center에 속하는 Cluster Points를 저장할 Vector를 생성한다.
이후 diffChange가 threshold보다 작을 때 까지 Clustering 과정을 반복한다.
// MyKMeans() 중 일부
while (diffChange > threshold) {
newCenter = 0;
for (int k = 0; k < n_cluster; k++) { ptInClusters[k].clear(); } // 모든 Cluster Points 정보 초기화
// 모든 Pixel에 대하여 Color Difference가 가장 적은 Cluster를 찾은 뒤 같은 Cluster로 정보 Update
findAssociatedCluster(src_img, n_cluster, clustersCenters, ptInClusters);
// 모든 Cluster에 대하여 각 Cluster의 평균 Intensity를 구하고 이전 값과의 차이를 계산한 뒤, 모든 Cluster의 차이의 평균값을 반환
diffChange = adjustClusterCenters(src_img, n_cluster, clustersCenters, ptInClusters, oldCenter, newCenter);
}
각 Cluster에 속하는 Points를 초기화 시킨다. 이후 모든 Pixel에 대하여 Color Difference가 가장 적은 Cluster를 찾은 뒤 Cluster Centor 정보를 Update한다. 이후 모든 Cluster에 대하여 각 Cluster의 평균 Intensity를 구하여 Cluster Center Intensity를 Update하고, 이전 값 과의 차이를 모든 Cluster에 대하여 계산한 평균을 구한다.
findAssociatedCluster()
void findAssociatedCluster(Mat imgInput, int n_cluster, vector<Scalar> clustersCenters,
vector<vector<Point>>& ptInClusters) {
// Image의 모든 픽셀에 대하여 반복
for (int r = 0; r < imgInput.rows; r++) {
for (int c = 0; c < imgInput.cols; c++) {
double minDistance = INFINITY;
int closestClusterIndex = 0;
Scalar pixel = imgInput.at<Vec3b>(r, c); // 현재 Pixel의 Intensity Value
// 모든 Cluster에 대하여 반복
for (int k = 0; k < n_cluster; k++) {
Scalar clusterPixel = clustersCenters[k]; // 각 Cluster의 Centor Pixel Intensity
double distance = computeColorDistance(pixel, clusterPixel); // Cluster의 중심 픽셀과, 현재 픽셀의 Intensity Difference
// Difference가 minDistance보다 적을 경우 즉, 모든 Cluster Center Point와 비교해서 가장 가까운 Cluster 찾음
if (distance < minDistance) {
minDistance = distance; // min Distance Update
closestClusterIndex = k; // 현재 픽셀의 가장 가까운 cluster Index 설정
}
}
ptInClusters[closestClusterIndex].push_back(Point(c, r)); // 가장 가까운 cluster Index의 Point로 추가
}
}
}
findAssociatedCluster()는 Random하게 선택 된 Cluster Center에 대하여 같은 Cluster로 속하는 Pixel를 찾는 과정이다. 영상의 모든 픽셀에 대하여 해당 픽셀의 Intensity를 가져온다. 이후 모든 Cluster에 대하여 반복하는데, 각 Cluster의 Center Intensity와의 차이를 computeColorDistance()를 통해 구한다. 만약 minDistance보다 현재 구한 차이값이 더 작을 경우 minDistance를 현재 구한 차이값으로 설정하고, 해당 픽셀의 Cluster Index를 해당 Cluster로 설정한다. 즉, 모든 Cluster Center Point와 현재 픽셀의 Color Difference를 구하고, 차이가 가장 적은 Cluster에 해당 픽셀을 군집화 한다.
computeColorDistance()
double computeColorDistance(Scalar pixel, Scalar clusterPixel) {
// BGR 각 Value의 Clolor Intensity Value Difference 계산
double diffBlue = pixel.val[0] - clusterPixel[0];
double diffGreen = pixel.val[1] - clusterPixel[1];
double diffRed = pixel.val[2] - clusterPixel[2];
double distance = sqrt(pow(diffBlue, 2) + pow(diffGreen, 2) + pow(diffRed, 2));
return distance;
}
computeColorDistance()는 두 Intensity의 차이를 루트 제곱 합 한 것이다.
adjustClusterCenters()
double adjustClusterCenters(Mat src_img, int n_cluster, vector<Scalar>& clustersCenters,
vector<vector<Point>>ptInClusters, double& oldCenter, double newCenter) {
double diffChange;
// 모든 Cluster에 대하여 반복
for (int k = 0; k < n_cluster; k++) {
vector<Point>ptInCluster = ptInClusters[k]; // 각 Cluster에 속하는 모든 Pixel Position
double newBlue = 0;
double newGreen = 0;
double newRed = 0;
if (ptInCluster.size() > 0) { // 포인트가 있을 때만 계산
// 모든 Pixel Position에 대하여 반복
for (int i = 0; i < ptInCluster.size(); i++) {
Scalar pixel = src_img.at<Vec3b>(ptInCluster[i].y, ptInCluster[i].x); // 해당 Pixel의 Intensity
newBlue += pixel.val[0];
newGreen += pixel.val[1];
newRed += pixel.val[2];
}
// Cluster에 속하는 모든 픽셀의 B,G,R Intensity를 더한 후 픽셀의 개수로 나눠서 평균을 구함
newBlue /= ptInCluster.size();
newGreen /= ptInCluster.size();
newRed /= ptInCluster.size();
}
else {
continue; // 포인트가 없는 클러스터는 건너뜁니다
}
// 계산한 평균 Intensity를 가지는 새로운 Pixel Intensity 생성
Scalar newPixel(newBlue, newGreen, newRed);
// 이전의 Cluster 중심 Intensity와 새로운 Intensity와의 Difference를 계산하여 newCenter에 더함
newCenter += computeColorDistance(newPixel, clustersCenters[k]);
// Cluster의 중심 Intensity를 평균값으로 Update
clustersCenters[k] = newPixel;
}
// Difference를 모든 Cluster에 대하여 구했으므로 Cluster의 개수로 나눠서 평균을 구함
newCenter /= n_cluster;
// 이전의 Difference의 평균과의 차이를 구함
diffChange = abs(oldCenter - newCenter);
// Difference Update
oldCenter = newCenter;
return diffChange;
}
adjustClusterCenters()는 Color Difference로 각 Cluster에 속하는 Pixel들을 찾은 뒤 각 Cluster의 Center Intensity를 재조정 해 주는 함수이다. 모든 Cluster에 대하여 반복하는데, ptlnCluster Vector에 해당 Cluster에 속하는 Pixel Position 정보를 가져온다. 모든 Pixel의 Intensity 정보를 cv::Scalar 객체 pixel에 가져온 뒤, 각 Channel의 Intensity Value를 각각 모두 더한다. 이후 픽셀에 개수로 나눠서 평균을 구한다. 이렇게 구한 평균값을 해당 Cluster의 새로운 Center Intensity로 할당한다. 이때, 이전 Center Intensity와의 차이를 구하여 newCenter에 저장하고 이를 모든 Cluster에 대하여 반복한다. 이후 Cluster의 개수로 newCenter를 나눠 줌으로써 변화량의 평균값을 구한다. 이는 추후 threshold와 비교되어 Clustering Algorithm을 지속해서 수행할지 판단된다.
만약 diffChange가 threshold보다 작아서 더이상 변화가 이뤄지지 않으면, while문을 빠져나온 뒤 applyFinalClusterToImage()를 통해 Clustering 결과를 영상에 반영한다.
// MyKMeans 중 일부
// Clustering의 결과를 이미지에 반영
Mat dst_img = applyFinalClusterTolmage(src_img, n_cluster, ptInClusters, clustersCenters);
applyFinalClusterToImage()
Mat applyFinalClusterTolmage(Mat src_img, int n_cluster, vector<vector<Point>>ptInClusters,
vector<Scalar>clustersCenters) {
// 최종 이미지 생성
Mat dst_img(src_img.size(), src_img.type());
int32_t s32_I;
vector<pair<Scalar,int>> st_ClusterCenterIntensity;
vector<string> st_ClusterColor;
// 모든 Cluster에 대하여 반복
for (int k = 0; k < n_cluster; k++) {
// 각 Cluster에 속하는 Pixel Position Info
vector<Point>ptInCluster = ptInClusters[k];
// 각 Cluster에 속하는 Pixel Intensity를 Cluster Centor Pixel Intensity로 설정
for (int j = 0; j < ptInCluster.size(); j++) {
dst_img.at<Vec3b>(ptInCluster[j])[0] = clustersCenters[k].val[0];
dst_img.at<Vec3b>(ptInCluster[j])[1] = clustersCenters[k].val[1];
dst_img.at<Vec3b>(ptInCluster[j])[2] = clustersCenters[k].val[2];
}
st_ClusterCenterIntensity.push_back(make_pair(cv::Scalar(clustersCenters[k].val[0], clustersCenters[k].val[1], clustersCenters[k].val[2]), ptInCluster.size()));
}
sort(st_ClusterCenterIntensity.begin(), st_ClusterCenterIntensity.end(), compareCount);
for (s32_I = 0; s32_I < n_cluster; s32_I++)
{
if (MyBGR2HSVScalar(st_ClusterCenterIntensity[s32_I].first) != "Invalid")
cout << "Main Color: " << MyBGR2HSVScalar(st_ClusterCenterIntensity[s32_I].first) << endl;
}
return dst_img;
}
bool compareCount(const pair<Scalar, int>& a, const pair<Scalar, int>& b) {
return a.second > b.second;
}
모든 Cluster에 대하여 반복하여 해당 Cluster에 속하는 Pixel Position 정보를 가져온다. dst_img에서 해당 Pixel Position의 Intensity를 해당 Cluster의 Center Intensity로 설정한다. 이후 해당 Cluster의 Center Intensity와 Cluster에 속하는 Pixel의 개수를 st_ClusterCenterIntensity Vector에 저장한다.
해당 이미지를 대표하는 영역의 컬러를 추출하기 위해서 st_ClusterCenterIntensity를 해당 Cluster에 속하는 Pixel 개수를 기준으로 정렬한다. 해당 Cluster의 개수가 많다는 의미는 해당 이미지를 대표하는 색상을 띈다는 의미이다. 따라서 해당 Cluster의 Center Intensity가 무슨 색을 띄는지 확인하면 된다.
MyBGR2HSVScalar()
string MyBGR2HSVScalar(Scalar st_Color) {
double b, g, r, h, s, v;
b = (double)st_Color[0];
g = (double)st_Color[1];
r = (double)st_Color[2];
// Max, min 값 구하기
double MAX = max(max(b, g), r);
double MIN = min(min(b, g), r);
// <색상 변환 계산>
v = MAX;
s = v == 0 ? 0 : (MAX - MIN) / MAX; // v가 0이면 s는 0임
s *= 255; // s의 범위를 0~255까지 맞춰줌(uchar이므로)
// <오버플로우 방지>
if (MAX == MIN) { // MAX - MIN이 0일 때 예외처리
h = 0;
}
else if (MAX == r) {
h = 60 * ((g - b) / (MAX - MIN));
}
else if (MAX == g) {
h = 60 * (2 + (b - r) / (MAX - MIN));
}
else {
h = 60 * (4 + (r - g) / (MAX - MIN));
}
// 오버플로우 처리
h = h < 0 ? h + 360 : h;
Scalar NewHSV(h, s, v);
string Color = MyDecideColor(NewHSV);
return Color;
}
이전엔 영상에 대해서 BGR -> HSV로 색공간을 변형 하였지만, 이번엔 하나의 Scalar Intensity에 대하여 수행하였다. 이후, 변환된 HSV Value의 Color를 확인하기 위해서 MyDecideColor()의 인자로 넣는다.
MyDecideColor()
string MyDecideColor(Scalar st_Coloar)
{
double Min_S = 50;
double Min_V = 50;
double Max_S = 255;
double Max_V = 255;
if (st_Coloar[1] < Min_S || st_Coloar[1] > Max_S || st_Coloar[2] < Min_V || st_Coloar[2] > Max_V)
return "Invalid";
else if (MyInRangeScalar(st_Coloar, cv::Scalar(st_Parameter[0].first, Min_S, Min_V), cv::Scalar(st_Parameter[0].second, Max_S, Max_V)))
return "Red";
else if (MyInRangeScalar(st_Coloar, cv::Scalar(st_Parameter[1].first, Min_S, Min_V), cv::Scalar(st_Parameter[1].second, Max_S, Max_V)))
return "Red";
else if (MyInRangeScalar(st_Coloar, cv::Scalar(st_Parameter[2].first, Min_S, Min_V), cv::Scalar(st_Parameter[2].second, Max_S, Max_V)))
return "Orange";
else if (MyInRangeScalar(st_Coloar, cv::Scalar(st_Parameter[3].first, Min_S, Min_V), cv::Scalar(st_Parameter[3].second, Max_S, Max_V)))
return "Yellow";
else if (MyInRangeScalar(st_Coloar, cv::Scalar(st_Parameter[4].first, Min_S, Min_V), cv::Scalar(st_Parameter[4].second, Max_S, Max_V)))
return "Green";
else if (MyInRangeScalar(st_Coloar, cv::Scalar(st_Parameter[5].first, Min_S, Min_V), cv::Scalar(st_Parameter[5].second, Max_S, Max_V)))
return "Blue";
else if (MyInRangeScalar(st_Coloar, cv::Scalar(st_Parameter[6].first, Min_S, Min_V), cv::Scalar(st_Parameter[6].second, Max_S, Max_V)))
return "Purple";
}
S, V의 Min, Max Value는 젤 처음 영상의 색상 정보를 추출한 Value와 동일하게 하였고, 각 색상에 대한 H Value Range 역시 동일하게 하였다. 색상을 결정하기 위한 st_Color의 Intensity 정보를 각 색상의 Range와 비교하여 색상을 특정한다. 만약, 유효하지 않는 범위 내에 있다면 "Invalid"를 반환한다.
bool MyInRangeScalar(Scalar st_Coloar, Scalar st_Min, Scalar st_Max)
{
// HSV Min Value
double H_Min = st_Min[0];
double S_Min = st_Min[1];
double V_Min = st_Min[2];
// HSV Max Value
double H_Max = st_Max[0];
double S_Max = st_Max[1];
double V_Max = st_Max[2];
if (st_Coloar[0] >= H_Min && st_Coloar[0] <= H_Max && st_Coloar[1] >= S_Min && st_Coloar[1] <= S_Max && st_Coloar[2] >= V_Min && st_Coloar[2] <= V_Max)
return true;
else
return false;
}
확인하기 위한 st_Color Intensity가 각 색상의 Range에 포함되는지 확인하여 포함되면 true를 반환한다.



k를 5로 수행 결과 과일 영역의 색상을 Green, Yellow로 추출함을 확인할 수 있습니다. 1개의 Cluster는 배경을 나타내는 흰색으로 "Invalid"이기 때문에 출력되지 않았습니다.

이는 젤 처음 과일 영역을 컬러로 추출하였을 때 색상과 동일하며, K-Means Clustering 과정에서는 k=5이기 때문에 초록색 영역에 속하는 H Value를 Center로 하는 Cluster가 더 많이 존재하여 Green 색상이 더 많이 출력된 것으로 판단됩니다.
'2024 > Study' 카테고리의 다른 글
| [ 영상 처리 ] Ch9. Local Feature Detection and Matching(2) (0) | 2024.05.27 |
|---|---|
| [ 영상 처리 ] Ch9. Local Feature Detection and Matching(1) (1) | 2024.05.27 |
| [ 영상 처리 ] Ch6. Frequency Domain (0) | 2024.04.17 |
| [ 영상 처리 ] Part3-2. OpenCV Diagonal Edge Detection & Image Pyramid(C++) (0) | 2024.04.15 |
| [ 영상 처리 ] Part3-1. OpenCV Edge Detection(C++) (0) | 2024.04.15 |



