
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- AlexNet
- NLP
- 머신러닝
- machine learning
- C++
- 그래프 이론
- 강화학습
- hm3d
- 백준
- ubuntu
- dynamic programming
- image processing
- CS285
- r-cnn
- GIT
- CNN
- YoLO
- hm3dsem
- Reinforcement Learning
- Python
- DP
- UC Berkeley
- deep learning
- BFS
- LSTM
- 딥러닝
- MySQL
- RL
- opencv
- dfs
- Today
- Total
JINWOOJUNG
[EECS 498] Assignment 1. k-NN...(2) 본문
본 포스팅은 Michigan Univ.의 EECS 498 강의를 수강하면서 공부한 내용을 정리하는 포스팅입니다.
https://jinwoo-jung.tistory.com/122
[EECS 498] Assignment 2. KNN...(1)
본 포스팅은 Michigan Univ.의 EECS 498 강의를 수강하면서 공부한 내용을 정리하는 포스팅입니다.https://jinwoo-jung.tistory.com/120 [EECS 498] Assignment 1. PyTorch 101...(3)본 포스팅은 Michigan Univ.의 EECS 498 강의를
jinwoo-jung.com
6. KNN Classifier
이제 KnnClassifier Class를 생성 해 보자.
생성한 KnnClassifier를 바탕으로, KNN Classifier의 직관을 얻기 위해 임의의 학습 및 테스트 포인트, 클래스를 할당하고 시각화 해 보자.
class KnnClassifier:
def __init__(self, x_train: torch.Tensor, y_train: torch.Tensor):
self.x_train = x_train
self.y_train = y_train
def predict(self, x_test: torch.Tensor, k: int = 1):
dist = compute_distances_no_loops(self.x_train, x_test)
y_test_pred = predict_labels(dist, self.y_train, k)
return y_test_pred
앞서 생성한 함수들을 바탕으로 쉽게 구현할 수 있다.
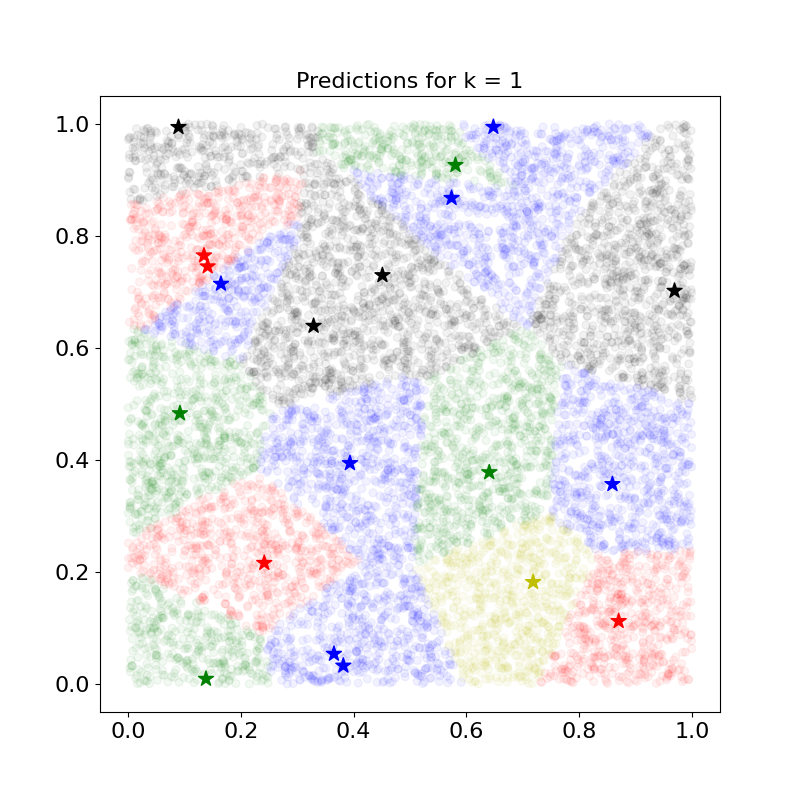
별이 학습 데이터, 원이 테스트 데이터를 시각화 한 것이다. 현재는 자신과 가장 가까운 학습 데이터의 클래스만(k=1) 고려됨을 확인할 수 있다.
시각화 한 학습 데이터의 클래스(색상)에 대해서 이질감이 느껴질 수 있는데, 현재 클래스 역시 랜덤하게 생성되었기 때문이다.

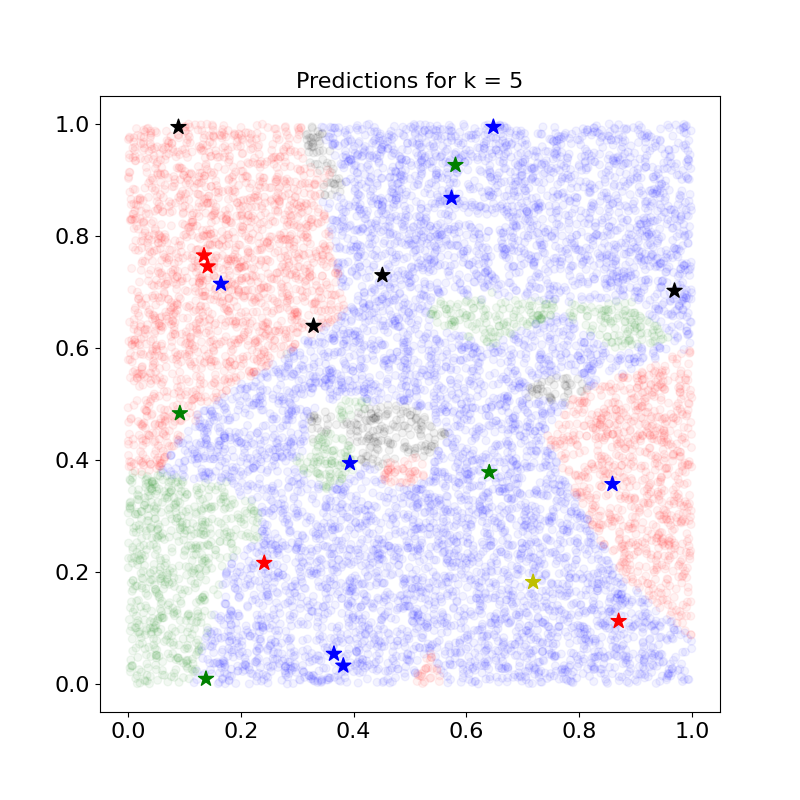
k 값이 증가될수록 Overfitting이 줄어듬을 확인할 수 있다. 하지만, 너무 많은 k를 고려함에 따라 클래스가 잘못 할당된 것 처럼 보이기도 하며, k개 안에 학습 데이터 클래스의 빈도수가 동일한 경우 더 작은 클래스로 할당되기에 납득되지 못하는 결과가 발생하기도 한다. 예를 들어, k=3인 경우 초록색 클래스를 가지는 학습 데이터 인근의 테스트 데이터도 빨간색 클래스로 할당되어있는데, 이는 빨간색 클래스가 더 작은 Index를 가지는 클래스이기 때문이다.
torch.manual_seed(0)
num_train = 5000
num_test = 500
x_train, y_train, x_test, y_test = eecs598.data.cifar10(num_train, num_test)
classifier = KnnClassifier(x_train, y_train)
classifier.check_accuracy(x_test, y_test, k=1)
classifier.check_accuracy(x_test, y_test, k=5)
# Got 137 / 500 correct; accuracy is 27.40%
# Got 139 / 500 correct; accuracy is 27.80%
실제 CIFAR-10 Dataset을 기반으로 동작시킨 결과 k=1일 때 27.4%, k=5일 때 27.8%로 둘다 낮은 비교적 낮은 성능을 보임을 확인할 수 있다.
7. Cross-validation
이전까지는 학습 데이터와 테스트 데이터를 분리하여, 학습 데이터를 이용하여 모델을 학습시키고, 이를 테스트 데이터를 활용해 검증하는 방식으로 진행하였다. 하지만, 고정된 테스트 데이터로 모델을 평가하고 튜닝하면 테스트 데이터에만 Overfitting 되는 문제가 발생한다. 따라서 교차 검증은 데이터의 모든 부분을 사용하여 모델을 검증하고, 최종적으로 테스트 데이터를 통해 성능을 평가한다.
torch.chunk(input: Tensor, chunks: int, dim: int = 0) → Tuple[Tensor, ...]
def knn_cross_validate(
x_train: torch.Tensor,
y_train: torch.Tensor,
num_folds: int = 5,
k_choices: List[int] = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100],
):
x_train_folds = []
y_train_folds = []
# num_folds 개의 동일한 크기로 train dataset을 분할
# 교차검증을 위한 데이터 분할
x_train_folds = list(torch.chunk(x_train, num_folds))
y_train_folds = list(torch.chunk(y_train, num_folds))
k_to_accuracies = {}
# 각 k 마다 그리고 교차 검증 과정에서 Test Set으로 선정 될 때 마다의 정확도를 저장하기 위한 Dictionary 초기화
k_to_accuracies = {k: [] for k in k_choices}
for fold in range(num_folds):
# Validation Dataset
x_val = x_train_folds[fold]
y_val = y_train_folds[fold]
# Validation Dataset을 제외한 Train Dataset
x_train_sub = torch.cat(x_train_folds[:fold] + x_train_folds[fold + 1:])
y_train_sub = torch.cat(y_train_folds[:fold] + y_train_folds[fold + 1:])
# k에 따른 KNN Accuracy 계산
for k in k_choices:
classifier = KnnClassifier(x_train_sub, y_train_sub)
y_pred = classifier.predict(x_val, k=k)
accuracy = torch.sum(y_pred == y_val).item() / y_val.size(0)
k_to_accuracies[k].append(accuracy)
return k_to_accuracies
먼저 교차 검증을 위해 입력받은 num_folds 개의 동일한 크기로 학습 데이터를 분리한다. torch.chunk를 사용하면 원하는 개수만큼 데이터를 쉽게 분할할 수 있다. 이후 num_folds에 대하여 Loop를 돌면서 Validation Dataset을 이전에 분할한 일부로 설정하고, 나머지를 Test Dataste으로 설정한다. 이를 통해 중복 없이 데이터의 모든 부분을 활용하여 모델을 검증할 수 있다.
이때, KNN의 경우 k는 Hyperparameter이기 때문에 최적의 k를 선정해야 한다. 따라서 입력받은 k_choices만큼 반복하여 각각의 k에 대한 정확도를 계산해 반환한다.
torch.manual_seed(0)
num_train = 5000
num_test = 500
x_train, y_train, x_test, y_test = eecs598.data.cifar10(num_train, num_test)
k_to_accuracies = knn.knn_cross_validate(x_train, y_train, num_folds=5)
for k, accs in sorted(k_to_accuracies.items()):
print('k = %d got accuracies: %r' % (k, accs))
k = 1 got accuracies: [0.263, 0.257, 0.264, 0.278, 0.266]
# k = 3 got accuracies: [0.239, 0.249, 0.24, 0.266, 0.254]
# k = 5 got accuracies: [0.248, 0.266, 0.28, 0.292, 0.28]
# k = 8 got accuracies: [0.262, 0.282, 0.273, 0.29, 0.273]
# k = 10 got accuracies: [0.265, 0.296, 0.276, 0.284, 0.28]
# k = 12 got accuracies: [0.26, 0.295, 0.279, 0.283, 0.28]
# k = 15 got accuracies: [0.252, 0.289, 0.278, 0.282, 0.274]
# k = 20 got accuracies: [0.27, 0.279, 0.279, 0.282, 0.285]
# k = 50 got accuracies: [0.271, 0.288, 0.278, 0.269, 0.266]
# k = 100 got accuracies: [0.256, 0.27, 0.263, 0.256, 0.263]
이를 통해 각각의 k에 대하여 학습 데이터의 일부를 검증 데이터로 분할하여 교차 검증한 정확도를 얻을 수 있다.
ks, means, stds = [], [], []
torch.manual_seed(0)
for k, accs in sorted(k_to_accuracies.items()):
plt.scatter([k] * len(accs), accs, color='g')
ks.append(k)
means.append(statistics.mean(accs))
stds.append(statistics.stdev(accs))
plt.errorbar(ks, means, yerr=stds)
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.title('Cross-validation on k')
plt.show()
결과를 조금 더 분석 해 보자. 각 k에 대하여 Accuracy를 시각화 하고, 평균과 표준편차를 시각화 하면 다음과 같다.

그렇다면, 최적의 k를 찾아야 한다.
def knn_get_best_k(k_to_accuracies: Dict[int, List]):
best_k = 0
best_accuracy = 0
for k, accuracies in k_to_accuracies.items():
mean_accuracy = torch.tensor(accuracies).mean().item()
if best_accuracy < mean_accuracy or (best_accuracy == mean_accuracy and k < best_k):
best_k = k
best_accuracy = mean_accuracy
return best_k
입력받은 k_to_accuracies는 Dictionary로 k 값이 Key, Value는 각 k에 대하여 교차검증한 정확도가 들어있다.
따라서 각 k에 따른 평균 정확도를 계산한 뒤, best_accuracy보다 mean_accuracy가 높거나, 혹은 accuracy가 같지만 k가 더 작은 경우 best value를 갱신하여 최종적으로 최적의 k를 계산할 수 있다.
# 교차 검증을 기반으로 최상의 Accuracy 확인
torch.manual_seed(0)
best_k = knn.knn_get_best_k(k_to_accuracies)
print('Best k is ', best_k)
# Best k is 10
classifier = KnnClassifier(x_train, y_train)
classifier.check_accuracy(x_test, y_test, k=best_k)
# Got 141 / 500 correct; accuracy is 28.20%
torch.manual_seed(0)
x_train_all, y_train_all, x_test_all, y_test_all = eecs598.data.cifar10()
classifier = KnnClassifier(x_train_all, y_train_all)
classifier.check_accuracy(x_test_all, y_test_all, k=best_k)
# Got 3386 / 10000 correct; accuracy is 33.86%
최종적으로 가장 정확도가 높은 k는 10이며, 이를 바탕으로 계산한 정확도는 33.86%의 정확도를 가짐을 알 수 있다.
'딥러닝 > Michigan EECS 498' 카테고리의 다른 글
| [EECS 498] Assignment 2. Linear Classifier...(2) (2) | 2024.12.29 |
|---|---|
| [EECS 498] Assignment 2. Linear Classifier...(1) (1) | 2024.12.28 |
| [EECS 498] Assignment 1. k-NN...(1) (1) | 2024.12.24 |
| [EECS 498] Assignment 1. PyTorch 101...(3) (1) | 2024.12.22 |
| [EECS 498] Assignment 1. PyTorch 101...(2) (0) | 2024.12.22 |



