
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- LSTM
- DP
- GIT
- CNN
- 그래프 이론
- AlexNet
- RL
- YoLO
- machine learning
- Reinforcement Learning
- hm3d
- dynamic programming
- ubuntu
- deep learning
- dfs
- 머신러닝
- Python
- real-time object detection
- 백준
- 강화학습
- NLP
- hm3dsem
- BFS
- opencv
- r-cnn
- MySQL
- eecs 498
- 딥러닝
- image processing
- C++
- Today
- Total
JINWOOJUNG
[ NLP ] 어간 추출(Stemming) & 표제어 추출(Lemmatization) 본문
본 포스팅은 [딥 러닝을 이용한 자연어 처리 입문]을 기반으로 공부한 내용을 정리하는 포스팅입니다.
https://wikidocs.net/book/2155
정규화 기법 중 동일한 의미지만 표기가 다른 단어를 통합하는 기법인 어간 추출(Stemming)과 표제어 추출(Lemmatization)에 대해서 알아보자.
표제어 추출(Lemmatization)
표제어(Lemma)는 한국어로 '표제어','기본 사전형 단어'의 의미를 가진다. 표제어 추출은 단어들로부터 표제어를 찾아가는 과정으로, 단어들이 다른 형태를 가지더라도, 그 뿌리(기본) 단어를 찾아서 단어의 수를 줄이는 과정이다.
표제어 추출을 하는 가장 섬세한 방법은 단어의 형태학적 파싱을 먼저 진행하는 것이다. 형태소는 '의미를 가진 가장 작은 단위'라는 의미이고, 형태학은 형태소로부터 단어를 만들어나가는 학문을 의미한다. 형태소는 다음과 같은 종류를 가진다.
- 어간(Stem) : 단어의 의미를 담고 있는 단어의 핵심 부분
- 접사(Affix) : 단어에 추가적인 의미를 주는 부분
형태학적 파싱은 이 두 가지 구성 요소를 분리하는 작업이다. 예를 들어 "cats"의 경우 고양이를 의미하는 어간 "cat"과 복수 형 접사 "-s"를 분리하는 과정이 형태학적 파싱이라고 할 수 있다.
NLTK에서는 WordNetLemmatizer를 통해 표제어를 추출할 수 있다. 표제어 추출은 어간 추출과 달리 단어의 형태가 적절히 보존되는 특징을 가지고 있다. 그럼에도, "dy","ha"와 같이 의미를 알 수 없는 단어가 출력되는데, 이는 표제어 추출기가 본래 단어의 품사 정보를 알아야만 정확한 결과를 얻을 수 있기 때문이다.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print('표제어 추출 전 :',words)
print('표제어 추출 후 :',[lemmatizer.lemmatize(word) for word in words])
# 표제어 추출 전 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
# 표제어 추출 후 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'life', 'fly', 'dy', 'watched', 'ha', 'starting']
WordNetLemmatizer는 입력으로 단어가 동사 품사라는 사실을 알려줄 수 있다. 즉, dies와 watched, has가 문장에서 동사로 쓰였다는 것을 알려준다면 표제어 추출기는 품사의 정보를 보존하면서 정확한 Lemma를 출력하게 된다.
print(lemmatizer.lemmatize('dies', 'v'))
# die
어간 추출(Stemming)
어간(Stem)을 추출하는 작업을 어간 추출(Stemming)이라 한다. 어간 추출은 형태학적 분석을 단순화 한 버전이자 동시에, 정해진 규칙을 보고 단어의 어미를 자르는 작업이라고 볼 수 있다. 즉, 섬세한 작업이 아니기 때문에 어간 추출 후 결과가 사전에 존재하지 않는 단어일 수 있다.
어간 추출 알고리즘 중 하나인 포터 알고리즘(Porter Algorithm)의 결과는 다음과 같다. 동작하는 과정은 단순히 Tokenization 이후 Stemming을 통해 어간을 추출하는 과정으로 해석할 수 있다.
Porter Algorithm은 다음과 같은 규칙을 가지고 있다. 이 외에도 몇몇 규칙들이 있으며, 규칙 기반으로 Stemming을 수행하기 때문에 사전에 존재하지 않는 단어들도 나올 수 있다.
- ALIZE -> AL
- formalize -> formal
- ANCE -> 제거
- allowance -> allow
- ICAL -> IC
- electricical -> electric
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
stemmer = PorterStemmer()
sentence = "This was not the map we found in Billy Bones's chest, but an accurate copy, complete in all things--names and heights and soundings--with the single exception of the red crosses and the written notes."
tokenized_sentence = word_tokenize(sentence)
print('어간 추출 전 :', tokenized_sentence)
print('어간 추출 후 :',[stemmer.stem(word) for word in tokenized_sentence])
# 어간 추출 전 : ['This', 'was', 'not', 'the', 'map', 'we', 'found', 'in', 'Billy', 'Bones', "'s", 'chest', ',', 'but', 'an', 'accurate', 'copy', ',', 'complete', 'in', 'all', 'things', '--', 'names', 'and', 'heights', 'and', 'soundings', '--', 'with', 'the', 'single', 'exception', 'of', 'the', 'red', 'crosses', 'and', 'the', 'written', 'notes', '.']
# 어간 추출 후 : ['thi', 'wa', 'not', 'the', 'map', 'we', 'found', 'in', 'billi', 'bone', "'s", 'chest', ',', 'but', 'an', 'accur', 'copi', ',', 'complet', 'in', 'all', 'thing', '--', 'name', 'and', 'height', 'and', 'sound', '--', 'with', 'the', 'singl', 'except', 'of', 'the', 'red', 'cross', 'and', 'the', 'written', 'note', '.']
어간 추출 속도는 표제어 추출보다 일반적으로 빠르며, Porter 어간 추출기는 정밀하게 설계되어 정확도가 높으므로 영어 자연어 처리에서 어간 추출을 하고자 한다면 가장 준수한 선택이다.
NLTK는 포터 알고리즘 외에도 랭커스터 스태머 알고리즘(Lancaster Stemmer Algorithm)을 지원한다.
각각의 알고리즘은 서로 다른 규칙을 기반으로 Stemming을 수행하기 때문에 그 결과가 차이나는 것을 확인할 수 있다.
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
porter_stemmer = PorterStemmer()
lancaster_stemmer = LancasterStemmer()
words = ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print('어간 추출 전 :', words)
print('포터 스테머의 어간 추출 후:',[porter_stemmer.stem(w) for w in words])
print('랭커스터 스테머의 어간 추출 후:',[lancaster_stemmer.stem(w) for w in words])
# 어간 추출 전 : ['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
# 포터 스테머의 어간 추출 후: ['polici', 'do', 'organ', 'have', 'go', 'love', 'live', 'fli', 'die', 'watch', 'ha', 'start']
# 랭커스터 스테머의 어간 추출 후: ['policy', 'doing', 'org', 'hav', 'going', 'lov', 'liv', 'fly', 'die', 'watch', 'has', 'start']
규칙 기반 알고리즘은 때때로 정확한 일반화가 되지 않을 수 있는데, 어간 추출 결과가 지나치게 일반화 되거나, 덜 되는 경우가 존재하기 때문이다. 예를 들어, "organization"의 어간 추출 결과는 "organ" 이지만, 이는 전혀 다른 뜻의 "organ"이라는 단어의 어간 추출 결과와 동일하다.
한국어 어간 추출
한국어는 다음과 같이 5언 9품사의 구조를 가지게 된다. 이때, 용언에 해당되는 '동사', '형용사'는 어간과 어미의 결합으로 구성되게 된다.
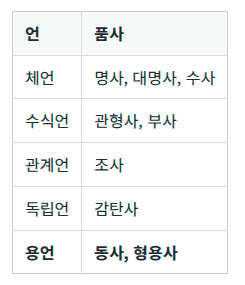
- 활용(Conjugation)
활용은 용언의 어간(Stem)이 어미(Ending)을 가지는 일을 말한다.
- 어간 : 용언(동사, 형용사)를 활용할 때, 원칙적으로 모양이 변하지 않는 부분. 활용에서 어미에 선행하는 부분.
- 어미 : 용언의 어간 뒤에 붙어서 활용하면서 변하는 부분, 여러 문법적 기능을 수행.
활용은 어간이 어미를 취할 때, 어간의 모습이 일정하다면 규칙 활용, 어간이나 어미의 모습이 변하는 불규칙 활용으로 나뉜다.
예를 들어, 어간 "먹"은 어미를 취할 때 모습이 일정하며, "-다","-고","-는" 등의 어미가 취해진다.
한편, "긋다"의 경우 "긋"이 어간, "-다"가 어미이지만, "그어서"의 경우 어간이 "그"로 변하게 된다. 따라서 이러한 경우를 불규칙 활용이라고 한다.
- 규칙 활용
규칙 활용은 어간이 어미를 취할 때, 어간의 모습이 일정하게 유지되는 경우이다.
- 불규칙 활용
불규칙 활용은 어간이 어미를 취할 때 어간의 모습이 바뀌거나 취하는 어미가 특수한 어미일 경우이다.
예를 들어 ‘듣-, 돕-, 곱-, 잇-, 오르-, 노랗-’ 등이 ‘듣/들-, 돕/도우-, 곱/고우-, 잇/이-, 올/올-, 노랗/노라-’와 같이 어간의 형식이 달라지는 일이 있거나 ‘오르+ 아/어→올라, 하+아/어→하여, 이르+아/어→이르러, 푸르+아/어→푸르러’와 같이 일반적인 어미가 아닌 특수한 어미를 취하는 경우 불규칙활용을 하는 예에 속한다.
이 경우에는 어간이 어미가 붙는 과정에서 어간의 모습이 바뀌었으므로 단순한 분리만으로 어간 추출이 되지 않고 좀 더 복잡한 규칙이 요구된다.
'NLP, LLM, Multi-modal' 카테고리의 다른 글
| [ Transformer to LLaMA ] Transformer..01 (0) | 2025.04.25 |
|---|---|
| [ VLM ] VLM Tasks와 Benchmarks..(1) (0) | 2025.04.15 |
| [ NLP ] Cleaning & Normalization (0) | 2025.04.14 |
| [ NLP ] Tokenization (0) | 2025.04.13 |
| [ NLP ] 자연어 처리를 위한 NLTK, KoNLPy (0) | 2025.04.13 |



