
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- real-time object detection
- MySQL
- opencv
- hm3d
- machine learning
- 머신러닝
- LSTM
- 그래프 이론
- C++
- hm3dsem
- DP
- ubuntu
- dynamic programming
- eecs 498
- GIT
- AlexNet
- 강화학습
- dfs
- CNN
- 백준
- NLP
- deep learning
- YoLO
- BFS
- r-cnn
- 딥러닝
- Python
- image processing
- Reinforcement Learning
- RL
- Today
- Total
JINWOOJUNG
[ VLM ] VLM Tasks와 Benchmarks..(1) 본문
Vision Language Model(VLM)
VLM은 Computer Vision과 Natural Language Processing을 결합한 모델로써, 이미지나 비디오와 같은 시각적 데이터와 텍스트 입력을 동시에 이해하고 처리할 수 있다.
VLM Tasks
- Visual Question Answering(VQA) & Visual Reasoning
VQA는 시각 질의응답을 의미하며, 이미지와 질문을 동시에 입력받아 정답을 출력하는 태스크이다. 아래 그림과 같이, 그림과 질문을 입력으로 받아 단답형 정답을 도출하는 형태이며, 이 태스크의 초기 벤치마크로는 [VQA: Visual Question Answering (Antol et al., 2015)] 논문이 있다.

VQA v1(2015) Benchmark는 2가지 종류의 Tasks가 존재한다.
- Open-ended Task : 주관식
- 단답에도 여러가지 정답이 존재할 수 있으므로, 각 질문에 대해 다른 사람에게 10개의 답을 얻은 뒤, 적어도 3명의 답과 같으면 정답으로 간주

- Multiple-choice Task : 18개의 선택지 중 선택
- 아래와 같이 주어진 후보군에 대해서 정답을 선택

Dataset의 경우 MS COCO 기반으로 각 Image 당 10개의 질문들로 구성된다.
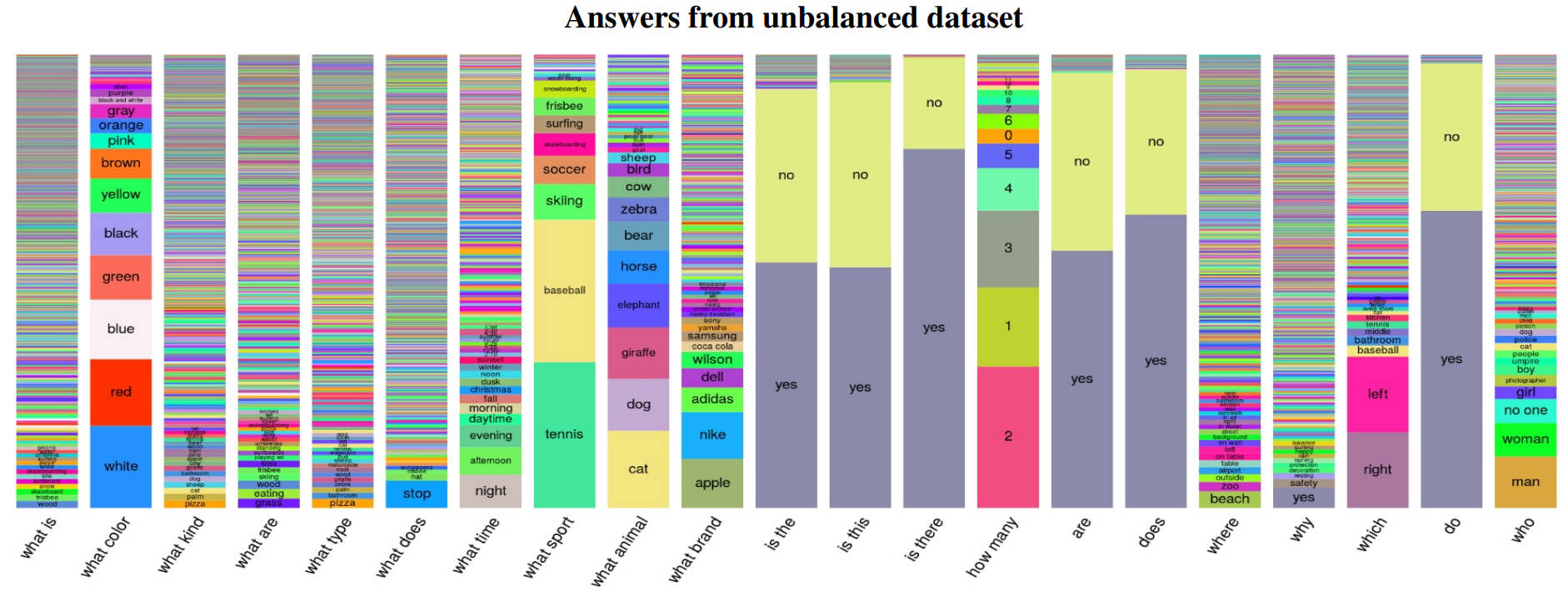
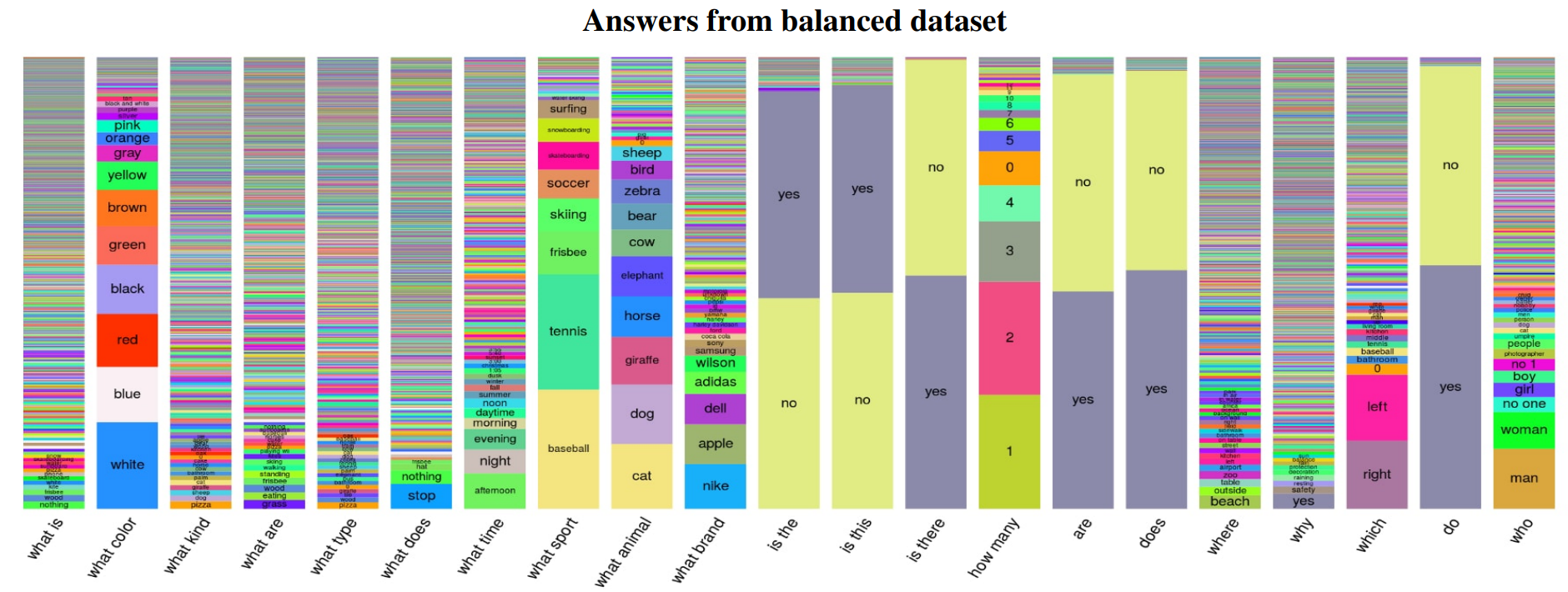
이후, VQA v2(2019) Benchmark로 업데이트 되게 되는데, 가장 큰 이유는 코퍼스 안에 존재하는 질문이나 답변이 세상에 존재하는 것들에 편향되어 있기 때문이다. 예를 들어, 가장 흔한 스포츠의 정답은 "Tennis" 이기 때문에, "What sport is"라는 질문에 답변을 하게 되면 41%의 Correct Answer를 얻을 수 있다. 또한, 대부분의 질문에 대하여 "Yes"라고 대답하면 87%라는 높은 정확도를 보이게 된다. 따라서 이러한 Dataset의 Balance를 조절한 것이 VQA v2이다.
실제로 비교 결과 큰 차이는 없지만 "yes","no" 비율 차이는 확실히 Balancing 된 것 처럼 보인다.
OK-VQA는 이미지와 질문 만으로는 정답을 알 수 없고, 외부 지식(Outside Knowledge)를 통해 답을 알 수 있는 질문들로 구성된 VQA를 의미한다. 아래의 질문과 같이 단순히 사진을 보고는 답할 수 없고, 외부 지식을 통해 정답을 유추할 수 있는 것이 OK-VQA이다.

OK-VQA의 경우 다음과 같이 총 10개의 카테고리 내에서 질문과 답변이 존재하게 된다.

그렇다면 어떻게 외부 지식을 가져와서 OK-VQA Task를 수행할 수 있을까?
먼저 External Knowledge Grounding을 진행하기 위해 다음과 같은 Step이 존재한다.
- Search Query 생성
- 질문에서 Non-stop Word를 추출
- Image로 부터 Visual Entity를 추출
- retrieved by Wikipedia search API
- 생성한 Search Query를 기반으로 검색엔진을 이용해서 Retrieval Task 수행
- Retrieval Task : Search Query에 대해서 외부 지식 소스로 부터 관련된 정보를 찾는 Task
- 생성한 Search Query를 기반으로 검색엔진을 이용해서 Retrieval Task 수행
- selecting the most relevant sentences from each article
- 찾아온 정보를 기반으로 정답을 유
Search Query를 생성하는 방법을 조금 더 자세히 살펴보자. VQA Dataset이므로 Image, Question이 제공된다. 따라서, Question으로 부터 Non-stop Word를 추출해서 Query를 구성할 수 있다. 또한, Image로 부터 Classification Task를 수행해서 뽑아낸 Visual Entity를 재구성해서 Query를 생성할 수도 있다.
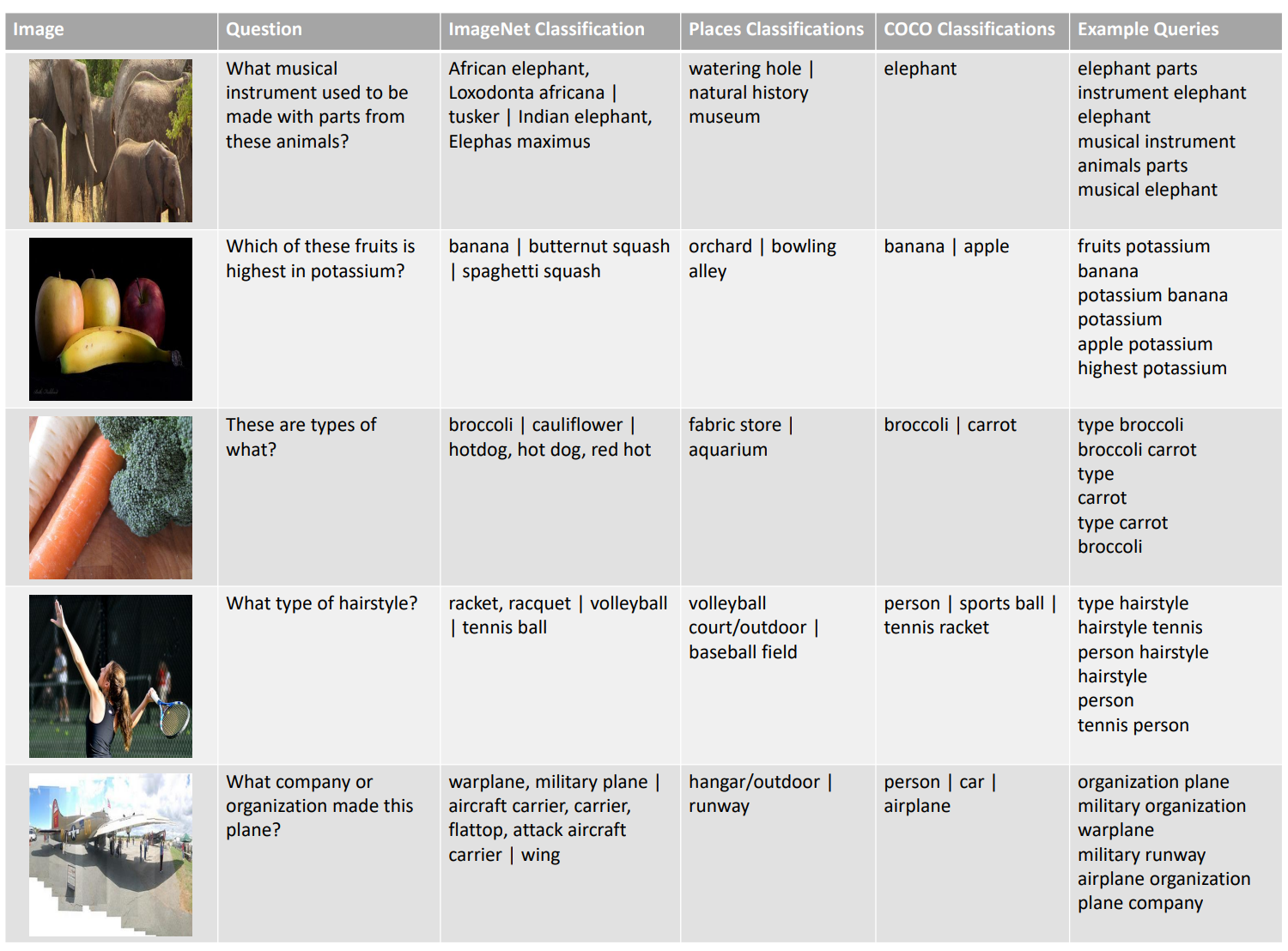
생성한 Search Query를 기반으로 찾은 정보를 이용해서 대답을 생성하게 된다.

마무리하며
이번 포스팅에서는 VQA, Visual Reasoning과 관련된 Benchmark를 살펴보았다. 더욱 다양한 Task가 존재하지만, 본 포스팅은 여기서 마무리 하고 앞서 설명한 3개의 Benchmark에 대해서 논문을 기반으로 분석한 뒤 이어나갈 생각이다.
- VQA: Visual Question Answering
- Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
- OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
Reference
- https://www.youtube.com/watch?v=8ofFVYPS8vA&list=PLMSTs9nojhsyO_PBhdKgaLvS-NqoPUQl_
- VQA: Visual Question Answering
- Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
- OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
'NLP, LLM, Multi-modal' 카테고리의 다른 글
| [ NLP ] BLEU Score: 기계번역 평가지표 (0) | 2025.04.25 |
|---|---|
| [ Transformer to LLaMA ] Transformer..01 (0) | 2025.04.25 |
| [ NLP ] 어간 추출(Stemming) & 표제어 추출(Lemmatization) (5) | 2025.04.14 |
| [ NLP ] Cleaning & Normalization (0) | 2025.04.14 |
| [ NLP ] Tokenization (0) | 2025.04.13 |



