
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- AlexNet
- CS285
- 머신러닝
- BFS
- image processing
- CNN
- MySQL
- LSTM
- deep learning
- r-cnn
- 강화학습
- NLP
- ubuntu
- machine learning
- YoLO
- 백준
- RL
- UC Berkeley
- C++
- Reinforcement Learning
- GIT
- Python
- dynamic programming
- 딥러닝
- hm3d
- dfs
- DP
- hm3dsem
- opencv
- 그래프 이론
- Today
- Total
JINWOOJUNG
n-Step Bootstrapping 본문
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar
수강 후 정리를 위한 포스팅입니다.
모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다.
Before This Episode
https://jinwoo-jung.tistory.com/32
Q-Learning
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar 수강 후 정리를 위한 포스팅입니다. 모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다. Before This Episode
jinwoo-jung.tistory.com
TD에서 파생된 SARSA, Q-Learning 모두 one-step으로 Q를 Update하였다.

단순히 one-step이 아닌 고려하는 step size를 늘려보자. n이 무한대로 가면 즉, terminal state 까지 가면 결국 Monte Carlo와 동일 해 진다. 따라서 둘의 장점을 모두 고려하기 위한 n-Step Solution이 등장하였다.
one-Step TD( = TD(0) )를 보면 state $s$에서 action $a$로 인한 reward $r$을 관측하고, 변화된 state $s'$에서 $max_{a'} Q(s',a')$이 update에 반영된다. 2-step을 예시로 들어보면, state $s'$에서 $a'$이 선택되고 return $r'$이 관측되었을 때, 변화된 state $s''$에서 $max_{a''} Q(s'',a'')$이 update에 반영된다. 이때, update되는 주체는 $Q(s,a)$이다.
아래 식은 TD 중 Q-Learning이 맞는 것 같습니다.
$$Q(s,a) \leftarrow Q(s,a) + \alpha[r+\gamma r' + {\gamma}^2 max_{a''}Q(s'',a'')]$$
state-value로 n-step TD를 식으로 보면 다음과 같다.


이미 MDP를 모르는 상황에서는 action-value가 더 유용함이 증명되었으므로, 이를 적용하여 n-step SARSA를 살펴보자.

one-step에서 n-step으로 갈 때, Target value를 Return을 이용해 표현함을 확인할 수 있다.

위 예시를 보면 두 차이를 확연히 알 수 있다. one-step의 경우 이전 1개의 Q만 Update되지만, n-step의 경우 $s_t -> s_{t+n}$의 모든 Q를 반영하기에 Update가 가능하다.
결국엔 Update 하는 것은 $Q_{t+n}(S_t,A_t)$인데, 어떻게 이게 가능한지 조금 의문이 들긴 하나, Return $G_{t:t+n}$을 계산하는 과정에서 고려되는 것으로 이해하였다.

하지만, Update과정에서 $\alpha$에 영향을 많이 받음을 위 그래프를 통해 알 수 있다. 또한, n에 따라서도 영향을 많이 받기 때문에 무엇이 Optimal한지는 단정지을 수 없다. 이를 해결하기 위해 각 step의 Return을 반영하는 과정에서 Weight의 차이를 주는 TD($\lambda$)가 등장하였다.
TD($\lambda$)

결국 TD($\lambda$)는 모든 n-step Returns를 평균내는데 1/n으로 나누는 것이 아닌, 각각의 Return에 서로다른 Weight를 부여한다. 즉, 모든 Weight의 합이 1이 되기 때문에 평균을 내는 것과 동일한 의미를 가지지만, 중요도를 달리할 수 있다.
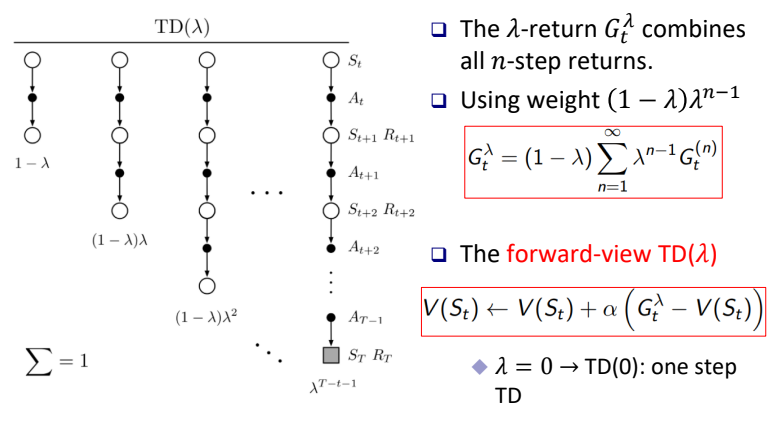
forward-view TD($\lambda$)의 경우 위와 같이 멀어질수록 Return에 더 작은 Weight를 부여한다. 이는 $\lambda$가 0~1의 범위를 갖기 때문이다. 하지만 이 경우 결국 terminal state로 도착했을 때 계산되어 update 되기 때문에 MC의 문제점인 너무 많은 시간이 요구되는 문제를 해결하지 못한다.
따라서 동일한 forward-view와 동일한 Behavior를 진행함이 증명되었지만, terminal state까지 도달하는 것이 아닌 실시간으로 Update가 진행되는 Backward-view TD($\lambda$)가 등장하였다.

Backward-view 역시 멀어질수록 Weight가 감소하지만 그 방향이 반대이다. 또한, 재방문하거나 방문했을 때, Weight를 관리하는 $e_t(s)$가 증가하여 가중치를 관리한다.

다음과 같이 방문했을 때 +1을 함으로써 가중치가 가까울수록 증가함을 알 수 있다. 따라서 Update 역시 매 step마다 진행된다.

one-step TD Error를 계산하여, 이를 $e_t(s)$를 곱하여 가중치를 부여하여 state-value를 update 한다.

'Reinforcement Learning' 카테고리의 다른 글
| Value Function Approximation (0) | 2024.02.04 |
|---|---|
| Model-based RL (1) | 2024.01.28 |
| Q-Learning (0) | 2024.01.20 |
| State-Action-Reward-State-Action (0) | 2024.01.20 |
| Temporal Difference Method (0) | 2024.01.19 |



