
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 강화학습
- ubuntu
- 딥러닝
- 백준
- BFS
- deep learning
- 그래프 이론
- r-cnn
- machine learning
- Reinforcement Learning
- dynamic programming
- YoLO
- image processing
- MySQL
- 머신러닝
- CNN
- AlexNet
- dfs
- CS285
- GIT
- C++
- hm3dsem
- LSTM
- Python
- UC Berkeley
- RL
- opencv
- hm3d
- NLP
- DP
- Today
- Total
JINWOOJUNG
Fast R-CNN...(1) 본문
Research Paper
0. Abstract
본 논문에서는 Fast Region-based Convolutional Network(Fast R-CNN) method를 제안한다. 기존 R-CNN 연구를 기반으로, 이전 연구와 비교하여 학습 및 테스트 속도를 개선하고 검출 정확도를 높였다.
Fast R-CNN은 VGG-16 Network 학습에 있어서 R-CNN의 9배, SPPnet의 3배 빠른 학습 속도를 보이며, R-CNN의 213배, SPPnet의 10배 빠른 테스트 속도를 보인다. 또한, PASCAL VOC 2012에서 더 높은 mAP를 보인다.
1. Introduction
최근 연구에서 Deep ConvNets는 Classification, Object Detection 성능 향상에 큰 역할을 하였다. 하지만, Object Detection의 복잡성으로 인해 최근 접근 방식은 느리고 비효율적인 다단계 파이프라인에서 모델을 학습시키고 있다.
이러한 복잡성은 객체 검출은 정확한 Localization이 요구되기 때문이다. 이를 위해선 크게 2가지 Task가 요구된다.
- 수많은 후보 객체 위치(Region Proposals) 처리
- Region Proposals의 부정확한 위치 정보 개선
본 논문에서는 최신 ConvNet 기반 객체 탐지기에 대한 간소화 된 학습 프로세스를 제안한다. 즉, Region Proposals의 Classification(SVM)과 위치 정보 개선(BBox Regressor)를 동시에 학습하는 Single-stage Train Algorithm을 제안한다. 제안하는 알고리즘은 VGG-16 Network를 기존 연구인 R-CNN보다 9배 빠른 학습속도, SPPnet 보다 3배 빠른 학습속도를 보이며, Runtime에서는 0.3초의 매우 짧은 이미지 처리 속도를 가진다. 또한, PASCAL VOC 2012에 대하여 mAP가 66%로, 기존 R-CNN의 62%의 최고 성능을 능가한다.
1.1 R-CNN and SPPnet
R-CNN은 Object Detection 성능을 향상시켰지만, 몇가지 단점이 있다.
- Training is a multi-stage pipeline
- Fine-tuning, SVM Fitting, BBox Regression
- Fine-tuning에서 학습한 Softmax Classifier는 SVM으로 대체되고, SVM은 추가적인 학습 요구
- Training is expensive in space and time
- 각 Region Proposals에 대한 Feature Vector를 독립적으로 계산해야 하며, SVM, BBox Regressor의 학습을 위해 저장해야 함
- Large Dataset일 수록 더 많은 Memory와 학습 시간이 요구됨
- Object detection is slow
- Test image에 대하여 각각의 Region Proposal에 대한 Feature Vector를 독립적으로 추출
- VGG-16 기반의 객체 검출은 하나의 Image에 대해 47s가 요구됨
R-CNN의 느린 속도는 계산을 공유하지 않고, 각각의 Region Proposal에 대한 Feature Vector 추출(ConvNet Forward Pass)이 독립적으로 수행되기 때문이다.
SPPnet은 계산을 공유하여 R-CNN의 속도를 향상시킨 Network이다. SPPnet은 Feature Vector 계산을 각각의 Region Proposal에 대해서 수행하는 것이 아닌, Input Image 전체를 ConvNet에 통과시켜 공유하는 Faeture Map을 계산한다. 각각의 Region Proposal에 대한 Feature Vector는 Featuire Map에서 Region Proposal에 속하는 부분만 추출하여 계산되며 이때, 고정된 크기로 Max Pooling하여 고정된 Output size를 가진다. 다양한 고정된 크기의 Max Pooling 출력을 연결하여 Spatial Pyramid Pooling 처럼 만들어 이를 FC Layer의 Input으로 입력한다.
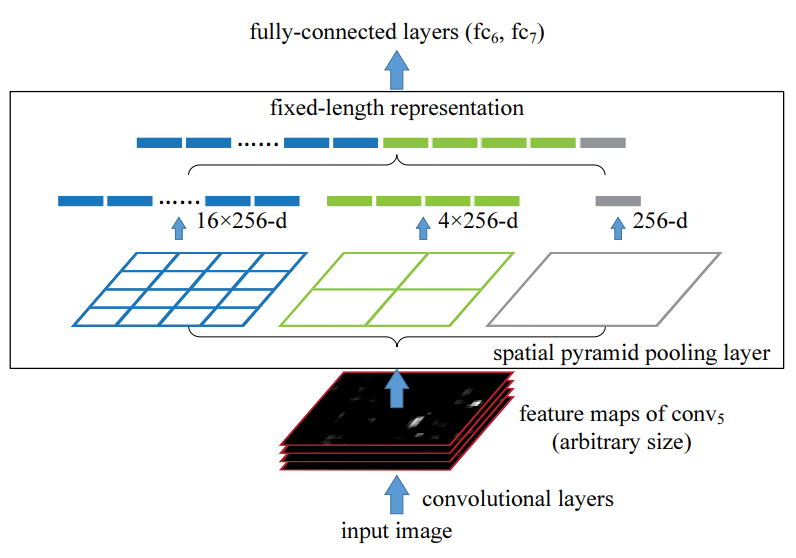
SPPnet은 R-CNN을 10~100배 빠르게 테스트 속도를 가속화 할 수 있으며, 학습 시간 역시 3배 줄일 수 있다. 하지만 여전히 Multi-stage Pipeline을 학습(R-CNN의 단점 1)해야 하며, Feature를 저장 (R-CNN의 단점 2) 해야 한다. 또한, Input Image에 대하여 추출한 Feature Map을 공유하여 Feature Vector가 계산되어 FC-Layer로 바로 연결되는데, 이때 여러 크기의 고정된 출력을 연결시키 때문에 Backpropagation을 통한 Conv Layer의 학습이 불가능하다.
1.2 Contributions
본 논문에서는 R-CNN, SPPnet의 단점을 보완하고, 학습과 테스트 속도가 상대적으로 빠르며 정확도가 개선된 Fast R-CNN을 제안한다. Fast R-CNN은 다음과 같은 장점을 가진다.
- R-CNN, SPPnet보다 더 높은 mAP
- Single-stage 학습 및 Multi-task loss 사용
- 모든 네트워크 계층 학습 가능
- Feature Caching을 사용하여 디스크 저장 공간의 불필요
Faster R-CNN은 Python과 C++(Caffe 사용)으로 구현되었다.
2. Faster R-CNN architecture and training
Fast R-CNN은 Input Image와 RoI를 Input으로 받는다. 먼저 SPPnet과 동일하게 Input Image를 Network의 Conv Layer를 통과시킨 뒤 하나의 Feature Map을 생성한다. 이후, Feature Map에서의 Object Proposal에 해당되는 RoI에 대하여 Max Pooling을 수행하는 RoI Pooling을 통해 고정된 크기의 Feature Vector를 획득하여 이를 FC Layer로 연결시킨다. FC Layer는 2가지 Output을 가지는데, $K$개의 Class와 1개의 배경에 속하는 확률을 계산하는 Softmax Output과 $K$개의 BBox를 보정하기 위한 $4 \ast K$개의 BBox Regressor Output을 가진다.
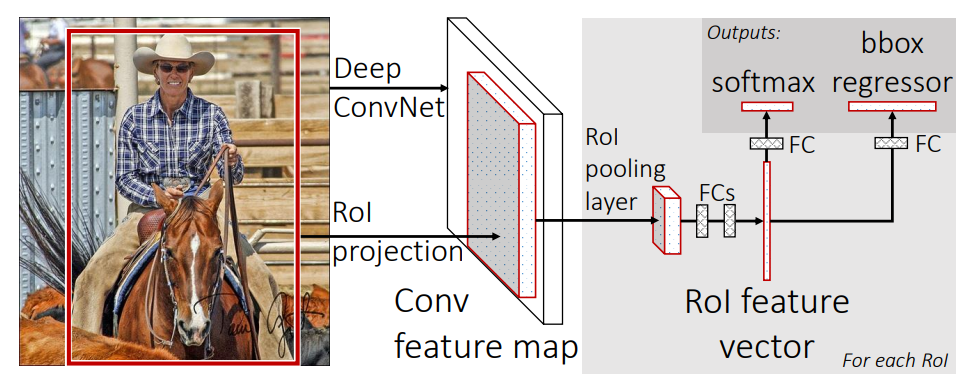
2.1 The RoI pooling layer
Feature Map 상에서 각 Object Proposal에 대한 RoI는 $(r,c,h,w)$로 정의되며, $(r,c)$는 왼쪽 상단 좌표, $(w, h)$는 Width, Height를 의미한다. RoI pooling layer는 FC Layer와 고정된 크기로 연결되기 위해, $(h,w)$를 $(H,W)$로 변환하는 작업이며 Max Pooling이 사용된다. 이때, $(H,W)$는 RoI와 무관한 Hyperparameter이다.
$(H,W)$의 크기로 변환하기 위해, RoI의 Sub-window는 대략 $(\frac{h}{H}, \frac{w}{W})$의 크기를 가지며, 각 Feature Map에 대하여 독립적으로 수행된다.
SPPnet에서 Multi-level에 대한 Max Pooling을 통해 Feature Vector를 추출하는 방식은 유사하나, Fast R-CNN은 Multi-Level이 아닌 Single-level을 가진다. 따라서, Backpropagation을 통해 Conv Layer를 학습하는 과정에서 Gradient를 계산해 Weight Update가 가능하기 때문에 Conv Layer를 학습시킬 수 있다.

2.2 Initializing from pre-trained networks
본 논문에서는 ImageNet으로 Pre-trained 된 3가지 네트워크에 대하여 실험을 진행한다. 각 네트워크는 5개의 Max Pooling Layer를 가지며, 각각 5~13개의 Conv Layer를 가진다. Pre-trained Model의 Wieght로 Fast R-CNN의 Weight를 초기화 할 때 3가지 변형이 이뤄진다.
- 마지막 Max Pooling $\to$ RoI Pooling
- 각각의 Network 구조와 FC Layer의 Input을 고려하여 $(H, W)$ 수정
- 마지막 FC Layer, Softmax를 2개의 Output Layer로 재구성
- Pre-trained 과정에서는 Classification으로 학습됨
- 2개의 Input을 가지도록 수정
- Image 및 Object Proposals에 해당되는 RoIs
2.3 Fine-tuning for detection
- Limitation of SPPnet Training
SPPnet의 학습은 Training Sample인 RoIs에 대한 Feature Vector가 하나의 Image가 아닌 서로 다른 Image에서 온다면 매우 비효율적이며, 이는 R-CNN의 학습 구조와 동일하다. 특히, RoI의 Receptive Filed 즉, Object Proposal이 Image 전체와 유사하게 매우 큰 경우, 각각의 Foreward 과정에서의 Input 역시 매우 크기 때문에 비효율적이다.
- Feature Sharing
본 논문에서는 Feature Sharing의 이점을 활용하여 계측적인 Sampling을 통해 네트워크의 학습을 매우 효율적으로 수행한다. SGD Mini-batch는 $N$개의 Image를 먼저 Sampling 한 뒤, 각각의 Image에 대하여 $\frac{R}{N}$개의 RoIs를 Sampling 한다. 이를 통해 같은 Image에 속하는 RoIs는 Feature(Featurea Map)을 공유할 수 있어 계산과 메모리를 효과적으로 사용할 수 있다.
만약 $N$을 감소시키면, Mini-batch 계산량이 줄어든다. $N=2, R=128$일 때, R-CNN, SPPnet에 비해 64배의 빠른 학습 속도를 보인다. 이때, $N$을 줄이면, 동일한 Image에 대하여 많은 RoIs를 추출하기 때문에 RoI간의 상관관계가 커져 학습 수렴 속도가 줄어들 수 있다. 하지만, $N=2, R=128$ 일 때, 매우 좋은 성능을 보임을 확인하였다.
- One Fining-tuning Stage
기존 R-CNN의 Multi-stage Pipeline을 가지는 학습 과정이 아닌, Fast R-CNN은 One Fine-tuning Stage를 가진다. 이를 통해 softmax classifier와 bounding box regressor를 함께 최적화한다.
Multi-task loss
Fast R-CNN의 두가지 Output은 다음과 같다. 이는 R-CNN에서 정의한 내용을 따른다.
- 각 RoI에 대한 이산 확률 분포
$p = (p_0, \cdots, p_K)$는 RoI가 $K+1$개의 각 Class에 속하는 확률로, Softmax를 통해 계산된다. 이때, 1은 Background이다.
- Bounding Box Regression Offsets
$t^k = (t_x^k, t_y^k, t_w^k, t_h^k)$ 는 각 객체 클래스 $K$에 대한 Offset으로, $ t_x^k, t_y^k$는 Scale-invarient Translation, $ t_w^k, t_h^k$는 Log-space Shift 이다.
각 학습 RoI는 GT class $u$, GT BBox Regression Target $v$로 Labled 된 GT 값을 가지며, 최종적인 Multi-task Loss $L$은 다음과 같다.
$$L(p, u, t^u, v) = L_{cls}(p, u) + \lambda[u \geq 1]L_{loc}(t^u, v) , \qquad (1)$$
이때, 식(1)의 $L_{cls}$는 Cross-Entropy Loss를 의미한다.
$L_{loc}$는 $u$가 1 이상인 $K$에 속할 때 계산되며, $u=0$인 경우는 Background 이므로, 이때는 계산을 하지 않는다. 따라서 $[u \geq 1]$은 $u=0$일 때만 0, 나머지는 1이 된다.
$$L_{loc}(t^u, v) = \sum_{i\in \left\{ x,y,w,h\right\}}^{} smooth_{L_1}(t_i^u - v_i)$$
이때, $t^u$는 BBox Regressor가 예측한 Offset이고, $v_i$는 RoI와 GT의 차이인 정답 Offset이다. 따라서 둘 차이가 최소가 되도록 $L_{loc}$가 정의된다. 이때, 예측과 GT의 차이가 커 $v_i$의 쿤산이 큰 경우 학습의 불안정성을 가져오기 때문에 평균이 0, 분산이 1이 되도록 정규화 한다.
$$smooth_{L_1}(x) = \begin{Bmatrix} 0.5x^2 \qquad \quad if |x| < 1 \\ |x| - 0.5 \qquad otherwise \end{Bmatrix}$$
$smooth_{L_1}(x)$는 다음과 같이 정의되는데, $L_1$ 손실 함수를 사용하여 Outlier에 대한 민감성을 낮춰, 예측 Offset과 GT의 차이가 큰 경우 Exploding Gradient(기울기 폭발)을 방지한다.
$\lambda$는 두 Loss간의 균형을 조절하는 것이며, 학습 과정에서는 $\lambda=1$로 설정하였다.
Mini-batch sampling
SGD Mini-batch는 $N=2, R=128$로 계층적 Sampling이 이루어진다.
이때, RoI의 경우 25%는 정답과 예측한 BBox의 IoU가 0.5 이상인 RoI로 채우며 이는 $u$가 1이상의 각각의 Calss Label을 가진다. 나머지 75%는 IoU가 0.1~0.5 사이의 값을 가지는 RoI로 채우며, 이는 Background로 $u=1$로 설정한다. Minimum IoU가 0.1로 설정된 이유는 Heuristic 한 Hard Example Mining으로, 모델이 학습하기 어려운 객체가 조금 겹쳐진 배경 예제들을 위한 설정이다.
Hard Negative Mining
배경과 객체의 불균형 문제를 해결하면서 모델의 높은 성능을 위해, Positive 비율을 줄이고, 객체의 일부가 겹치는 배경인 Negative 비율을 늘린 Mini-batch를 구성하여 모델을 학습
Backpropagation through RoI pooling layers
Backpropagation을 통해 RoI pooling layer를 거쳐 Gradient가 전달되는 과정을 생각 해 보자.
$x_i$는 RoI pooling layer의 Input인 Feature Map의 i번째 Activation Value로 실수이다. $y_{rj}$는 $r$번째 RoI에 대하여 RoI pooling layer를 거친 $j$번째 Output Value로 실수이다. 따라서 $y_{rj}$는 다음과 같이 계산된다.
$$y_{rj} = x_{i^{\ast}(r, j)}$$
즉, $r$번째 RoI의 RoI pooling layer를 거친 $j$번째 Output Value에 해당되는 값이 $x_{i^{\ast}(r, j)}$인 것이다. 이때,
$i^{\ast}(r, j) = argmax_{i' \in R(r,j} x_{i'}$와 같이 계산되므로, 이는 Max Pooling을 의미하며, $R(i,j)$는 Max Pooling을 하는 RoI의 Sub sample에 속하는 Index 집합을 의미한다.
결국 Fast R-CNN의 Forward Pass 중 RoI pooling layer의 과정을 수식화 한 것이며 이때, $x_i$는 여러 RoI의 $y_{rj}$에 해당될 수 있다.
RoI pooling layer의 Backward Function은 Loss에 대한 $x_i$의 편미분으로 계산된다.
$$\frac{\partial L}{\partial x_i} = \sum_{r}^{}\sum_{j}^{}[i=i^{\ast}(r,j)]\frac{\partial L}{\partial y_[rj]}$$
결국, Max Pooling을 거치기 때문에 $x_i$가 $y_rj$에 해당되는 경우만 누적해서 계산하면 되며, $ \frac{\partial L}{\partial y_[rj]}$는 Upstream Gradient로 Backpropagation 된다.
SGD hyper-parameter
최종 학습률은 Per-learning Rate와 Global Learning Rate의 곱으로 이뤄진다.
- Per-learning Rate
- 1 for Weight
- 2 for Bias
- Global Learning Rate
- VOC Dataset에 대하여 30,000 Mini-batch 반복동안은 0.001, 이후 10,000번 반복동안은 0.0001
- Large Datset에 대해서는 Iteration 증가
- Momentum : 0.9
- Parameter Decay : 0.0005 for Weight, Bias
2.4 Scale invariance
Scale에 불변한 객체 검출을 위해 2가지 방법을 비교한다.
- "brute force" learning
- Input Image의 크기를 고정시켜 모델이 스스로 Scale 불변성을 학습
- Multi-scale approach
- Image pyramid를 사용하여 다양한 스케일의 객체 탐지 유도
- 학습 과정에서는 Input Image를 Random하게 Scale을 증강
- 테스트 과정에서는 Image pyramid를 사용하여 여러 Scale에서의 Region Proposal을 추출하여 객체를 고정된 크기로 정규화
Multi-scale approach의 경우 여러 Scale로 Image를 Scaling 하면, 원본 이미지에서 작은 객체는 확대된 이미지에서, 원본 이미지에서 큰 객체는 작은 이미지에서 적절한 크기로 나타나기에, 고정된 크기의 객체로 정규화가 가능하다.
3. Fast R-CNN detection
Fast R-CNN의 Forward pass는 Input을 Image와 $R$개의 Object Proposals를 받아 이뤄진다. Test 과정에서 $R$은 약 2,000개로 설정되며, 더 많은 개수에 대해서도 고려한다. Image Pyramid를 사용하는 경우, RoI 즉, Input Image에 대하여 Object Proposal의 크기가 $224^2$에 가깝도록 RoI가 설정된다. 이는 앞서 설명한 고정된 크기의 객체로 정규화 하는 과정이다.
각각의 Object Proposal $r$에 대하여 Forward Pass의 Output은 2가지로, 각각의 클래스에 속할 확률 분포 $p$와 예측한 Bounding Box Offset이다. $p$는 $Pr(class=k|r) \overset{\underset{\mathrm{\Delta }}{}}{=} p_k$로 계산되며, 각각의 Class에 대하여 독립적으로 NMS를 수행한다.
3-1. Truncated SVD for faster detection
Object Detection 과정에서 Object Proposal에 대하여 Forwrard pass를 진행해야되기 때문에, FC Layer에서의 계산이 많이 소모된다. 본 논문에서는 Truncated SVD를 사용하여 FC Layer에서의 계산 속도를 가속한다.




