
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝
- YoLO
- Reinforcement Learning
- 백준
- real-time object detection
- 그래프 이론
- ubuntu
- BFS
- dfs
- RL
- CNN
- r-cnn
- hm3dsem
- DP
- opencv
- NLP
- hm3d
- image processing
- deep learning
- dynamic programming
- LSTM
- GIT
- MySQL
- eecs 498
- C++
- 강화학습
- AlexNet
- Python
- 머신러닝
- machine learning
- Today
- Total
JINWOOJUNG
Fast R-CNN...(2) 본문
https://jinwoo-jung.tistory.com/139
Fast R-CNN...(1)
Research PaperFast R-CNNSPPnet 0. Abstract 본 논문에서는 Fast Region-based Convolutional Network(Fast R-CNN) method를 제안한다. 기존 R-CNN 연구를 기반으로, 이전 연구와 비교하여 학습 및 테스트 속도를 개선하고 검
jinwoo-jung.com
4. Main results
본 논문에서 제안하는 Fast R-CNN은 다음과 같은 결과를 가진다.
- VOC07, 2010, 2012 Dataset에 대한 최고 수준의 mAP
- R-CNN, SPPnet에 비해 빠른 학습 및 테스트 속도
- VGG-16의 Conv Layer를 Fine-tuning하여 mAP의 향상
4.1 Experimental setup
본 논문에서는 ImageNet을 기반으로 Pre-trained 된 3가지 모델을 사용한다.
- AlexNet : $S$
- VGG_CNN_M_1024 : $M$
- AlexNet과 동일한 깊이지만 더 넓음
- VGG-16 : $L$
모든 실험은 Single-scale 학습 및 테스트를 진행하였다. 이때, $s$는 600으로, Input 영상의 가장 짧은 변의 길이를 $s$로 비율은 유지한 채 Rescale 한다.
4.2 VOC 2010 and 2012 results
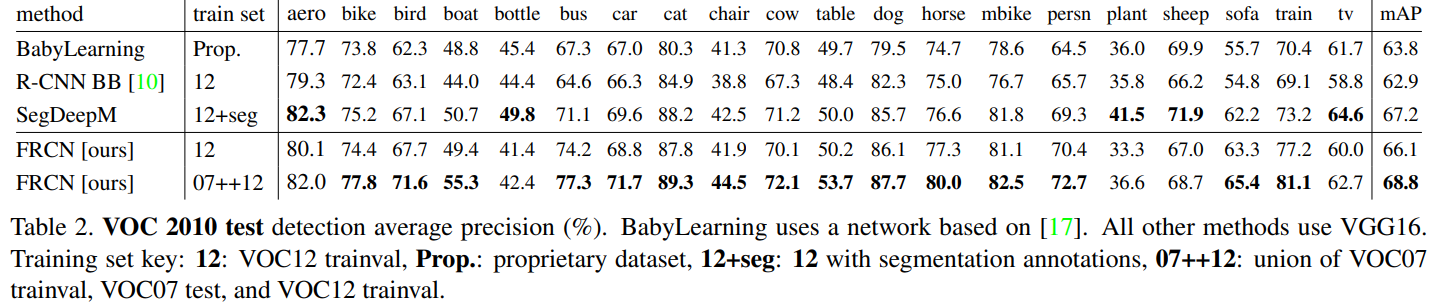
VOC 2010, 2012 Dataset에 대한 성능 평가는 Fast R-CNN과 리더보드의 다른 모델들을 비교한다. 리더보드의 모델 중 NUS_NIN_c2000, BabyLearning methods의 경우 Network-in-Network의 변형(1x1 Conv Layer를 추가해서 비선형성 학습)으로 추정되며, 다른 Method는 사전 학습된 VGG16으로 초기화된다.
VOC 2012 Dataset에 대하여 Fast R-CNN은 최고 성능인 65.7% mAP를 보이며, 추가적인 데이터 셋에서는 68.4% mAP의 성능을 보인다. 이는 다른 모델보다 100배 이상의 빠른 속도를 나타내는데, 다른 모델은 느린 R-CNN Pipeline을 기반으로 하기 때문이다.

VOC 2010 Dataset에 대하여 SegDeepM은 Fast R-CNN보다 높은 성능인 67.2% mAP를 보인다. 하지만, 해당 모델은 R-CNN의 Object Detection 결과와 $O_2P$ 기반의 Semantic Segmentation 결과를 결합하여 Markov Random Field(MRF)로 처리한 네트워크의 결과이다. 하지만, Fast R-CNN은 추가적인 Data로 학습한 결과 68.8% mAP로 더 높은 성능을 보인다.
$O_2P$는 공분산을 통한 Feature Representation의 한 종류로, Segmantic Segementation Task에 많이 사용되는 방법이다.
4.3 VOC 2007 results
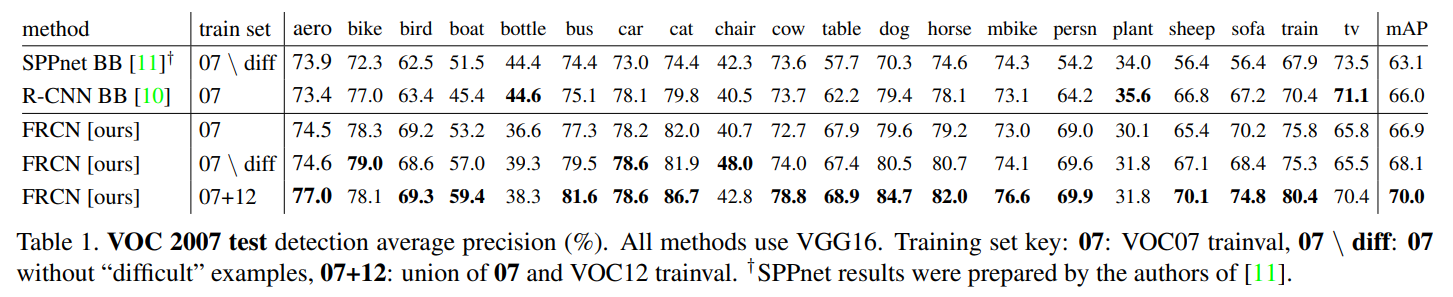
VOC 2007 Dataset에 대하여 Fast R-CNN은 R-CNN, SPPnet과의 성능을 비교한다. 이때, SPPnet은 학습과 테스트 과정에서 5개의 Scale을 사용하였다.
Fast R-CNN은 단일 스케일을 기반으로 Conv Layer를 Fine-tuning하여 66.9% mAP를 달성하였다. 이는 SPPnet의 63.1%, R-CNN의 66.0% mAP와 비교하여 높은 수치이며, SPPnet과 동일하게 "difficult" Example을 제외한 Dataset으로 학습시킨 결과 68.1%로 더 높은 성능을 보인다.
4.4 Training and testing time
Fast R-CNN은 R-CNN, SPPnet과 Training Time, Test Rate(Image Processing Time) 등을 비교한다.
L(VGG16)에 대하여 Fast R-CNN은 더 빠른 학습 속도와 이미지 처리 시간을 보임을 확인할 수 잇다. 또한, SVD를 사용함으로써 연산 속도는 더 빨라졌으며, Feature를 캐싱(저장)하지 않기 때문에 디스크 저장 공간이 요구되지 않는다.
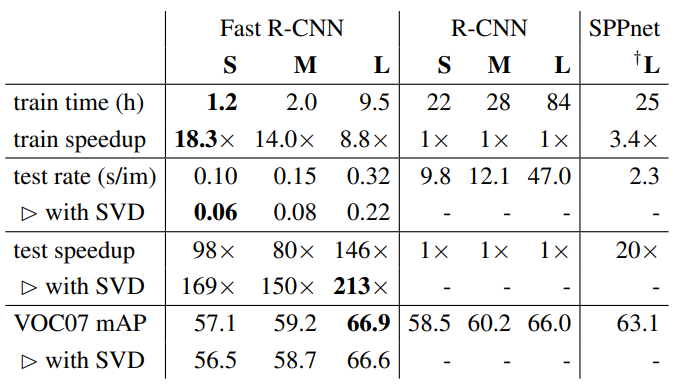
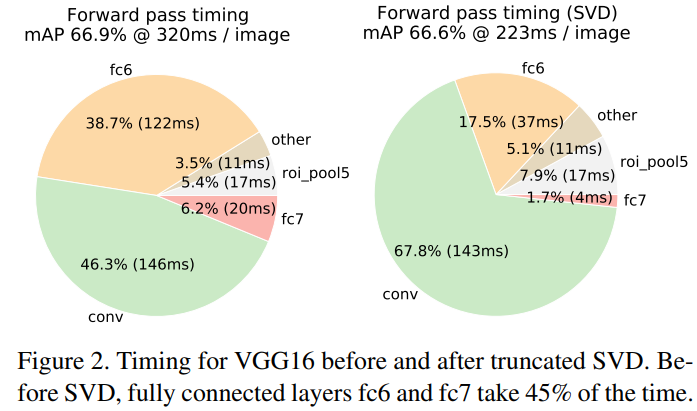
Truncated SVD를 사용함으로써 약간의 mAP 감소(0.3%)는 있지만, 30% 이상의 객체 검출 시간을 단축시킴을 확인할 수 있다. 아래 그림에서 fc6 Layer의 상위 1024, fc7 Layer의 상위 256개의 특이값을 사용하여 Runtime을 감소시키고, mAP손실이 거의 없음을 확인할 수 있다. 특히, FC Layer 에서의 요구되는 연산 속도가 확연히 줄음을 확인할 수 있다.
4.5 Which layers to fine-tune?
상대적으로 덜 깊은 Network가 고려된 SPPnet에서의 가설인 "오직 FC Layer만 Fine-tuning해도 충분히 좋은 성능을 보인다"를 본 논문에서는 더 깊은 Network(VGG16)에 대해서 해당 가설은 유효하지 않다고 가정한다.
이를 입증하기 위해, model $L$(VGG-16)을 사용하는 Fast R-CNN에 대하여 Conv Layer를 freeze시킨 뒤 FC Layer만 Fine-tuning 한 경우와 정확도를 비교하여 Conv Layer를 Fine-tuning 하는 것이 깊은 네트워크에서 중요함을 입증한다.
실제로 FC Layer만 Fine tuning 한 결과 Conv Layer도 Fine-tuning 한 경우보다 약 5.5% mAP가 낮음을 확인할 수 있다.

그렇다고 모든 Conv Layer를 학습시킬 필요는 없다. Conv1은 mAP에 영향을 주지 않음이 입증 되었으며, Conv 2_1 이상의 Conv Layer를 모두 Fine-tuning 시키는 경우 0.3% mAP의 성능 향상이 존재하지만, 1.3배의 학습 시간이 더 걸리기 때문에 실용적으로 효과적이지 않다. 따라서 본 논문에서는 $L$의 경우 Conv 3_1 위쪽 Layer를 Fine-tuning하며, 더 작은 $S$, $M$은 Conv 2_1 위쪽 Layer를 Fine-tuning한다.
'딥러닝 > 논문' 카테고리의 다른 글
| SSD: Single Shot MultiBox Detector (0) | 2025.01.20 |
|---|---|
| You Only Look Once: Unified, Real-Time Object Detection(YOLO) (0) | 2025.01.19 |
| Fast R-CNN...(1) (1) | 2025.01.12 |
| Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)...(2) (0) | 2025.01.11 |
| Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)...(1) (0) | 2025.01.11 |



