
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- DP
- MySQL
- opencv
- 머신러닝
- dfs
- Python
- NLP
- CNN
- 딥러닝
- dynamic programming
- CS285
- r-cnn
- UC Berkeley
- YoLO
- LSTM
- RL
- BFS
- 백준
- C++
- hm3dsem
- 강화학습
- Reinforcement Learning
- AlexNet
- machine learning
- GIT
- image processing
- deep learning
- 그래프 이론
- ubuntu
- hm3d
- Today
- Total
JINWOOJUNG
You Only Look Once: Unified, Real-Time Object Detection(YOLO) 본문
Research Paper
Abstract
YOLO는 Object Detection Task의 새로운 접근 방식이다. Object Detection Task를 하나의 Regression Problem으로 정의하며, 하나의 Network로 구현되어 End-to-End 최적화가 가능하다.
One-stage Detector인 YOLO는 45fps의 실시간성을 보인다.
YOLO는 더 많은 Loclization Error를 보이지만, 배경에 대한 FP를 줄이며, 객체에 대한 일반적인 특징을 잘 학습한다.
Introduction
Object Detection Task에서 좋은 성능을 보이는 Model은 Classifier를 Detection으로 변형한 구조를 가진다. 특히, R-CNN의 경우 Region Proposal을 생성하고, 각 Region Proposal에 대하여 SVM Classifier의 Classification, BBox Regressor의 Regression을 통해 Object Detection Task를 수행한다. 이러한 복잡한 구조는 느리고 최적화에 어렵고, 각각에 대하여 별도의 학습이 요구되기에 End-to-End 학습이 불가능하다.
본 논문에서는 Object Detection을 하나의 Regression Problem으로 정의하며, Input Image에서 바로 Bounding box coordinate와 class probability를 예측한다.

YOLO는 다음과 같은 이점을 가진다.
- 매우 빠르다
- Object Detection을 하나의 Regression 문제로 정의
- 복잡한 Pipeline이 요구되지 않음
- 45fps의 실시간성
- 전체 이미지에 대한 전역적 탐색
- Region Proposal이 아닌 Input Image에서 예측 수행
- Contex Information을 함께 학습
- Fast R-CNN에 비해 Background Error가 $\frac{1}{2}$배 감소
- 객체의 일반화 된 특징을 잘 학습
- 새로운 도메인이나 데이터에 잘 적응
YOLO는 빠르게 객체 검출이 가능하지만, 특히 작은 객체에 대한 정밀한 위치화는 떨어져 정확도는 SOTA 대비 약간 떨어진다.
Unified Detection
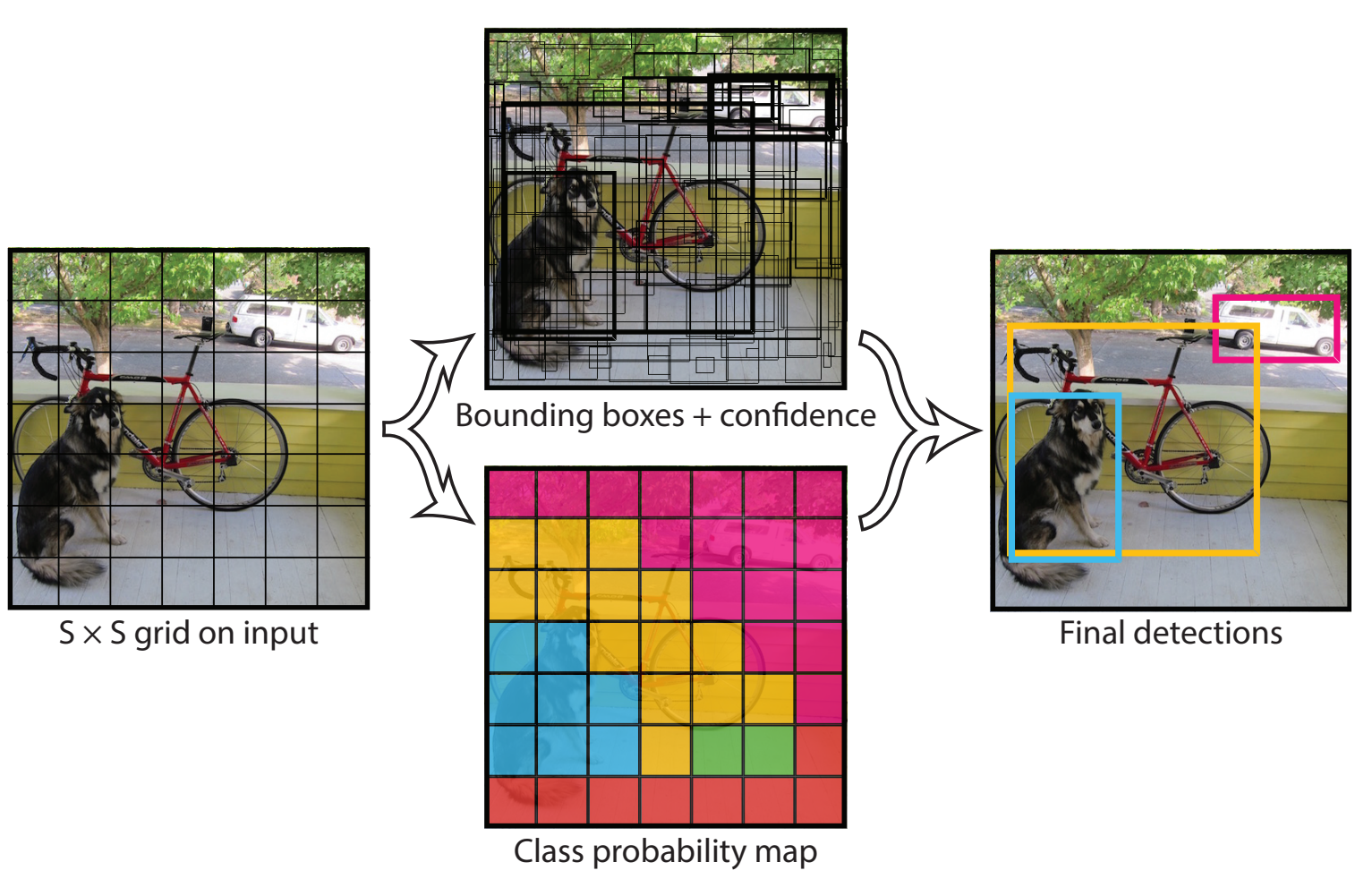
Input Image를 $S \times S$ Gride로 나눈다. 각각의 Grid Cell은 Model이 예측하는 Bounding Box의 중심좌표가 해당 Cell에 속하는 경우 해당 객체를 검출할 "Responsible"를 가진다. 각각의 Grid Cell은 $B$ 개의 Bounding Box와 Confidence를 예측한다.
Confidence란 해당 Bounding Box가 객체가 있다는 신뢰도와 예측한 Bounding Box의 정확도를 포함하는 개념이다. Confidece를 아래와 같이 객체가 있을 확률과 GT와의 IoU의 곱으로 표현할 수 있다.
$$Confidence = Pr(Object) \ast IOU^{turth}_{pred}$$
또한, 각각의 Grid Cell은 $C$ Conditional Class Probabilities $Pr(Class_i|Object)$를 예측한다. 이는, 각 Gird Cell이 책임이 있는 Boundig Box의 개수와 상관없이 1개의 클래스에 대해서만 예측한다.
각각의 Bounding Box는 $x, y, w, h, confidence$를 가지며, $(x,y)$는 각 Grid Cell에 대한 상대적인 위치, $(w,h)$는 전체 이미지에 대한 상대적인 위치이다. Confidence는 $x,y,w,h$로 표현되는 모델이 예측한 Bounding Box와 모든 GT와의 IoU이다.
Confidence는 $x,y,w,h$로 표현되는 모델이 예측한 Bounding Box와 모든 GT와의 IoU이다.
왜 모든 GT와의 IoU를 계산하는 걸까?
Test 과정에서는 Conditional Class Probability와 각각의 Box Confidence Prediction $Pr(Object) \ast IOU^{turth}_{pred}$를 곱한다. $C$는 조건부 확률이기에, 각 Grid Cell이 Class $i$일 확률과 GT와의 IoU의 곱으로 표현된다.
$$Pr(Class_i|Object) \ast Pr(Object) \ast IOU^{turth}_{pred} = Pr(Class_i) \ast IOU^{turth}_{pred}$$
Test인데 GT를 어떻게 알 수 있지?
최종적으로 YOLO의 Output은 $S \times S \times (B \ast 5 + C)$로 계산할 수 있다.
Network Design

YOLO Network는 CNN과 유사하다. 초기 Conv Layer에서는 전체 이미지에 대하여 Feature를 추출하고, FC Layer에서 Probability와 Coordiate Output을 예측한다.
Train
ImageNet 1000-class Competition Dataset(Classification)으로 Convolutional Layers를 Pre-train 한다. 위 구조에서 초기 20개의 Conv Layer만 Pre-training한다.
Pre-training 이후 위 구조로 변경하여 모델을 학습한다. 이때, 4개의 Conv Layer, 2개의 FC Layer는 Random Initialization 한다. 작은 객체에 대한 검출도 고려해야 하기 때문에, 224x224의 Input Image를 448x448로 Upscale 한다.
마지막 Layer를 제외한 모든 Layer는 Leaky Rectified Linear Activation Function을 사용하며 이때, $x<0$에서의 기울기는 0.1을 가진다. 마지막 Layer는 모델이 예측한 것을 그대로 반환하는 선형 활성화함수를 이용한다.
- Loss
YOLO의 목표는 mAP의 최대화 즉, Classification 뿐만 아니라 더 정확한 Localization에 초점을 두고 있다.
본 논문에서는 Bounding Box Coordinate Prediction에 대한 Loss를 증가시켜 정확한 Localziation에 가중치를 주었다.
또한, $\lambda_{coord}=5, \lambda_{noobj}=0.5$로 설정하여 객체를 포함하지 않는 Box에 대한 Confidence Prediction Loss를 낮추었다. 이는 영상의 대부분은 객체가 없는 배경이기 때문에 동일한 가중치로 설정하면, 대부분의 Grid가 Confidence=0이 되도록 학습되기 때문이다.
마지막으로, Bounding Box의 Width, Height가 아닌 제곱근을 한 값을 예측하도록 한다. 이는 작은 크기의 객체의 큰 차이가 큰 크기의 객체의 작은 차이보다 더 중요도가 높기 때문이다. 따라서 값이 더 커질수록 변화에 덜 민감하다록 제곱근을 씌운다. ($y=\sqrt{x}$를 생각 해 보자)

전체적인 Loss Function은 위와 같다.
각각의 부분적인 Loss는 $\sum_{i=0}^{S^2}, \sum_{j=0}^{B}$를 가짐을 확인할 수 있다. 이때, $i$는 Grid Cell Index, $j$는 각 Grid Cell에서 예측한 $B$개의 Bounding Box의 Index이다. Predict 과정에서는 각 Grid Cell이 $B$개를 예측하지만, Training 과정에서는 각 Grid Cell에게 1개의 Bounding Box를 예측하도록 "Responsible"(책임)을 부여한다.
따라서, $1^{obj}_ij$는 $i$번째 Grid Cell이 $j$번째 Bounding Box에 "Responsible"을 가지는 경우 1, 아니면 0이 된다. 즉, 각 Grid Cell의 특정 Bounding Box에 대한 BBox Loss, Confidence Loss를 계산한다.
객체가 없는 경우 $1^{noobj}_ij$는 1이 되며, 이때 Confidence 손실을 계산하고 객체가 없는 경우는 $\lambda_{noobj}$의 Weight를 가지게 된다.
마지막으로, 각 Grid Cell에 Object가 있는 경우에만 Probability Loss를 계산한다.
- Train Hyperparameter
초기 학습률이 높으면 Gradient가 불안정 하여 발산할 수 있기에, 첫번째 Epoch는 $10^{-3} \to 10^{-2}$으로 천천히 증가시킨다. 이후 75 Epoch 동안 $10^{-2}$, 30 Epoch 동안 $10^{-3}$, 30 Epoch 동안 $10^{-4}$으로 점차 감소한다.
Overfitting을 방지하기 위해 처음 FC Layer 이후 $p$는 0.5로 Dropout을 적용하였으며, 다양한 Random Scaling, Translation, HSV 색공간 에서의 Exposure, Saturation 조절 등 다양한 Augmentation을 수행함.
Test
Train과 동일하게 진행하나, 객체의 크기가 크면 여러 Grid Cell에 겹쳐서 존재할 수 있기 때문에 NMS를 적용한다.
Limitation of YOLO
1) 각 Grid Cell은 $B$개의 Bounding Box와 1개의 Class만 예측하는 공간적 제약을 받는다. 따라서 작은 객체들이 Group을 지어 있는 경우 정확한 객체 검출에 어렵다.
2) YOLO는 Train Dataset에 존재하는 객체를 기반으로 학습하기 때문에, 일반화에 어렵다. 즉, 동일한 객체임에도 다른 비율과 구성을 가진 객체에 대한 일반화가 어렵다.
3) Downsampling Layer를 가지기 때문에 객체의 세부적인 특징들을 학습하기 어렵다.
4) 큰 객체와 작은 객체를 동일한 가중치로 Loss Function을 계산하기 때문에, 큰 객체의 작은 오차와 작은 객체의 큰 오차가 동일하게 반영되어 작은 객체에 대한 정확한 Localization이 어렵다. 이는 Localization Error가 Two-stage Detector에 비해 많은 이유에 해당된다.
Experiment

YOLO는 Two-stage Detector에 비해 mAP는 다소 떨어지나, 확실한 실시간성 성능을 확보한다.

특히, bottle, plant와 같은 작은 객체에 대하여 mAP가 더 낮음을 확인할 수 있다.
Summary
YOLO는 객체 검출을 위한 통합된 모델로, Simple하고 Input Image에 대하여 바로 학습 가능하다. 특히, Classifier-based Approach가 아닌, 객체 검출을 하나의 Regression Problem으로 정의하여 E2E 학습이 가능하게 한다.
YOLO는 새로운 도메인에 대한 일반화가 잘 된다. 즉, 다양한 응용 분야, 다양한 Domain에 적용 가능하다.
YOLO는 다양한 환경에서 학습 후 다른 도메인에 쉽게 적용 가능하다. 하지만, Train Dataset으로 부터 객체 검출을 학습하기 때문에, 동일한 Category에 대한 새로운 유형(서로 다른 비율)의 일반화는 어려우며 작은 객체에 대한 낮은 정확성을 보인다.
따라서 논문의 마지막에 얘기하는 일반화는 다양한 Domain에서 활용 가능하다로 해석하는게 좋을 것 같다.
'딥러닝 > 논문' 카테고리의 다른 글
| Focal Loss for Dense Object Detection(RetinaNet) (0) | 2025.01.22 |
|---|---|
| SSD: Single Shot MultiBox Detector (0) | 2025.01.20 |
| Fast R-CNN...(2) (0) | 2025.01.12 |
| Fast R-CNN...(1) (1) | 2025.01.12 |
| Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)...(2) (0) | 2025.01.11 |



