
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- machine learning
- YoLO
- dynamic programming
- DP
- ubuntu
- eecs 498
- LSTM
- MySQL
- AlexNet
- r-cnn
- hm3dsem
- real-time object detection
- image processing
- opencv
- hm3d
- Reinforcement Learning
- BFS
- 머신러닝
- GIT
- 그래프 이론
- C++
- Python
- 강화학습
- CNN
- RL
- 백준
- NLP
- 딥러닝
- dfs
- deep learning
- Today
- Total
JINWOOJUNG
Focal Loss for Dense Object Detection(RetinaNet) 본문
Research Paper
Abstract
Two-stage Detector는 높은 Accruacy를 보인다. 그에 반해, One-stage Detector는 빠르고 간단하지만, Accuracy가 상대적으로 낮음을 확인할 수 있다. 본 논문에서는 낮은 Accuracy는 Dense Detector의 학습 과정에서 전경과 배경의 클래스 불균형 때문임을 발견하였다.
Dense Detector
One-stage Detector는 전체 이미지에 대하여 Grid Cell으로 나누고, 각 Cell에 대하여 서로 다른 크기와 종횡비의 Anchor Box를 기반으로 학습하게 된다. 그렇기에 One-stage Detector를 "Dense" Detector라 칭한다.
본 논문에서는 클래스 불균형을 해결하기 위해 표준 교차 엔트로피 손실을 재구성하여 잘 분류된 예제에 대한 손실을 낮추는 Focal Loss를 제안한다. 이는, Sparse한 어려운 예제에 학습을 집중시키고, 많은 쉬운 음성 예제에 학습이 집중되는 것을 방지한다.
간단한 Dense Detector RetinaNet을 통해 Focal Loss의 성능을 평가하며, One-stage Detector의 빠른 속도를 유지하면서 Accuracy를 Two-stage Detector를 능가하는 수준으로 향상시켰다.
Introduction
본 논문에서는 학습 과정에서의 클래스 불균형(Class Imbalance)가 One-stage Detector의 Accuracy 저하의 가장 큰 원인이기에, 이를 해결하는 새로운 Loss Function인 Focal Loss를 제안한다.
Two-stage Detector는 적은 수의 Region Proposal을 생성하여 배경 수를 줄인다. 또한, 고정된 배경-전경의 비율이나 Online Hard Example Mining(OHEM)을 통해 배경과 전경의 균형을 유지한다.
반면, One-stage Detector은 더 많은 객체 후보를 생성하며, 전체 이미지에 대하여 전역적으로 Dense하게 생성한다. One-stage Detector 역시 Sampling Heuristics를 적용하지만, 여전히 쉽게 분류되는 배경 이미지에 지배되어 비효율적이다. 이러한 비효율성은 Bootstrapping 혹은 Hard Example Mining을 통해 해결한다.
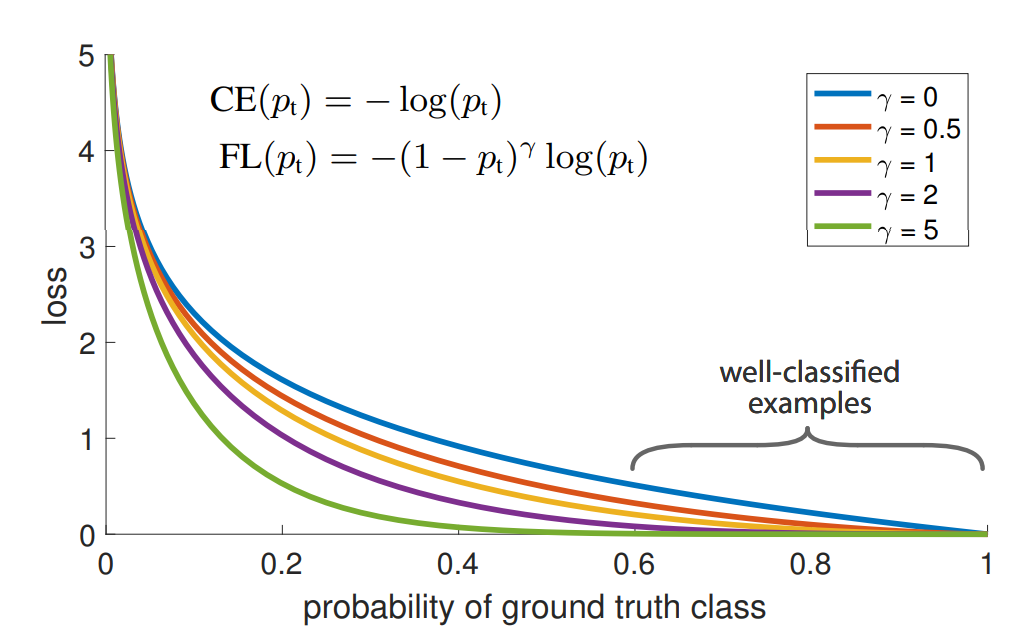
본 논문에서 제안하는 Focus Loss는 동적으로 Scaling 된 Cross-entropy Loss이다. 즉, 동적으로 올바른 Class에 대한 신뢰도가 증가함에 따라 Scaling을 0으로 감소시켜 Loss를 낮춘다. 이를 통해, 쉬운 예제의 기여도를 낮추고, 모델이 어려운 예제에 빠르게 집중하도록 할 수 있다. 이는 기존 해결책 보다 더 효과적이며, 정확한 형태는 요구되지 않고 다양한 변형에서 유사한 결과를 도출할 수 있다.
Focal Loss를 실험하기 위해 간단한 One-stage Detector인 RetinaNet을 설계하여 성능을 평가한다. RetinaNet은 Dense Sampling을 수행하며, 효율적인 Feature Pyramid와 Anchor Box를 사용한다.
Focal Loss
Focal Loss는 One-stage Detector의 학습 과정에서 발생하는 전경과 배경의 Extreme Inbalance를 해결하기 위한 방법이다.
Focal Loss는 Binary Cross Entropy($CE$) Loss에서 확장되었다.
$$CE(p, y) = \left\{\begin{matrix} -log(p) \qquad \qquad if\quad y = 1 \\ -log(1-p) \qquad otherwise \end{matrix}\right.$$
Binary 이므로, $y=1$이 GT가 전경인 경우, $y=-1$은 배경인 경우를 의미하며, $p \in [0,1]$은 모델이 $y=1$이라고 추정한 확률을 의미한다. 이를 재구성하면, $CE(p, y) = CE(p_t) = -log(p_t)$로 표현할 수 있다.
$$ p_t = \left\{\begin{matrix} p \qquad \; \ if \quad y=1 \\ 1-p \quad otherwise \end{matrix}\right.$$
$CE$ Loss는 Figure 1에서 가장 위 파란색 그래프며, 여전히 $p_t \geq 0.5$ 즉, 쉽게 예측 가능한 경우에 대해서도 큰 값을 가져 Loss에서 큰 비중을 차지함을 확인할 수 있다. 이러한 경우가 중첩된다면, 최종 Loss는 쉽게 예측 가능한 경우에 지배당하게 된다.
- Balanced Cross Entropy
따라서 더 적은 전경에 대한 Loss에 가중치를 부여한 것이 Balanced Cross Entropy Loss이다.
$$ CE(p_t) = =\alpha_tlog(p_t)$$
이때, $\alpha_t$는 $p_t$와 동일한 방식으로 정의되며, 일반적으로 Class Frequency의 역수나 교차 검증을 통해 결정된다.
- Focal Loss
$alpha$ Balance 만으로는 쉽고 어려운 Negative에 대한 비교는 불가능하다. 본 논문에서는 쉬운 예제에 대한 가중치를 감소시켜 학습 과정에서 Hard Negative에 집중할 수 있도록 하는 Focal Loss를 제안한다.
$$FL(p_t) = -(1-p_t)^\gamma log(p_t)$$
이때, $(1-p_t)^\gamma$는 Modulating Factor(조정 인자), $\gamma \geq 0 $는 조정 인자를 조절하는 Parameter이다.
$p_t$가 작고 잘못 분류된 경우 즉, Hard Negative에 대해서는 Modulating Factor가 1에 가깝기 때문에 Focal Loss에 영향을 주지 않는다. 하지만, $p_t$가 큰 경우 즉, Easy Negative는 Modulating Factor가 0에 가깝게 되어 Loss의 가중치를 줄이게 된다.
또한, $\gamma$를 통해 가중치를 Smooth하게 조절하며, $\gamma=0$인 경우는 $CE$와 동일하게 동작하며, 증가할수록 Modulating Factor에 의한 Focusing 효과가 커진다.
본 논문에서는 $\gamma=2$일 때, 가장 성능이 좋다고 언급한다. 이때, $p_t \approx 0.968$인 경우 Loss를 1000배 감소시키며, $p_t \leq 0.5$인 경우는 4배 감소시켜 Hard Negative에 Focuing 하게 된다.
실질적으론 $\alpha$-balanced Form을 사용하며, 고정된 형태는 없고 유사한 형태여도 비슷한 효과를 낼 수 있다.
$$FL(p_t) = -\alpha_t(1-p_t)^\gamma log(p_t)$$
또한, Loss Layer를 Sigmoid와 결합시켜 $p$를 계산하도록 한다.
Class Imbalance and Model Initialization
앞서 정의한 Focal Length를 사용하는 과정에서, 초기 $p$를 0.5로 설정하게 된다면, $y=-1$인 배경에 의한 Loss가 Total Loss를 지배하게 되어 초기 학습 과정의 불안정을 야기한다.
본 논문에서는, 희소한 전경 클래스에 대해 추정하는 $p$의 초기값에 대한 Prior(사전확률) 개념을 도입하며, 모델이 희소 클래스에 대해 낮은 $p$를 추정하도록 설정한다(p = 0.01)
이는 Cross Entropy와 Focal Loss 모두의 학습 안정성을 향상시킨다.
'딥러닝 > 논문' 카테고리의 다른 글
| VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection (0) | 2025.02.05 |
|---|---|
| PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (0) | 2025.02.03 |
| SSD: Single Shot MultiBox Detector (0) | 2025.01.20 |
| You Only Look Once: Unified, Real-Time Object Detection(YOLO) (0) | 2025.01.19 |
| Fast R-CNN...(2) (0) | 2025.01.12 |



