
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- C++
- DP
- ubuntu
- image processing
- Python
- 강화학습
- BFS
- hm3dsem
- dynamic programming
- RL
- deep learning
- GIT
- Reinforcement Learning
- r-cnn
- AlexNet
- real-time object detection
- CNN
- LSTM
- 머신러닝
- NLP
- 그래프 이론
- eecs 498
- dfs
- MySQL
- 딥러닝
- machine learning
- hm3d
- YoLO
- 백준
- opencv
- Today
- Total
JINWOOJUNG
PointPillars: Fast Encoders for Object Detection from Point Clouds 본문
PointPillars: Fast Encoders for Object Detection from Point Clouds
Jinu_01 2025. 2. 18. 13:05Papaer
Introduction
자율주행차는 차량, 보행자, Cyclist와 같은 동적 객체를 검출해야한다.
LiDAR 3D PointCloud Data(PCD)를 기반으로 한 Object Detection Task는 Bottom-up Pipeline을 통해 연구되어왔다. 즉, Hand-crafted Feature를 기반으로 지면 제거 후 객체에 대한 Clustering, Classification이 진행된다.
단순히 Hand-crafted Feature만으론 한계가 있기 때문에 Computer Vision 분야의 Deep Learning Methods가 도입되면서 PCD에 적용하려고 했지만, Sparse하고 3D 구조인 PCD의 특성 상 2D Image에 적용되는 Convolutional Network 그대로 적용할 수 없다. 따라서 PCD를 2D Image로 투영한 Bird's Eye View(BEV)를 활용하려고 시도하였지만, Sparse한 PCD의 특성 상 BEV에서 더더욱 Sparse하기 때문에 문제가 있다.
최근 연구에는 PointNet을 기반으로 한 VoxelNet이 존재하며, 매우 놀라운 성능을 보이지만 4.4Hz의 추론시간이 요구되기에 Real-time Object Detection이 불가능하다. 이를 보완하기 위한 SECOND는 속도를 향상시켰지만, 3D Convolution을 사용하기에 병목현상이 존재한다.
본 논문에서 제안하는 PointPillars는 2D Convolutional Layers만 사용한 E2E 학습이 가능한 3D Object Detection Method이다. PCD에 대하여 Pillar라는 PCD로 구성된 수직 기둥으로 부터 Feature를 추출하고 처리하기에, VoxelNet과 달리 수직 방향에 대한 처리가 불필요하다. 또한, 3D PCD를 Pillars로 처리하여 최종적으로 2D Convolution Layers만 활용하기 때문에 효율적이다.
PointPillars는 오직 LiDAR PCD만 활용하여 KITTI Detection Challenges에서 Cars, Pedstrians, Cyclists에 대한 우수한 성능을 보이며 62Hz의 매우 빠른 동작 속도를 보인다.
PointPillars Network
PointPillars는 PCD를 Input으로 하여 Cars, Pedstrians and Cyclists에 대한 Heading이 고려된 3D Boxes를 추론한다.
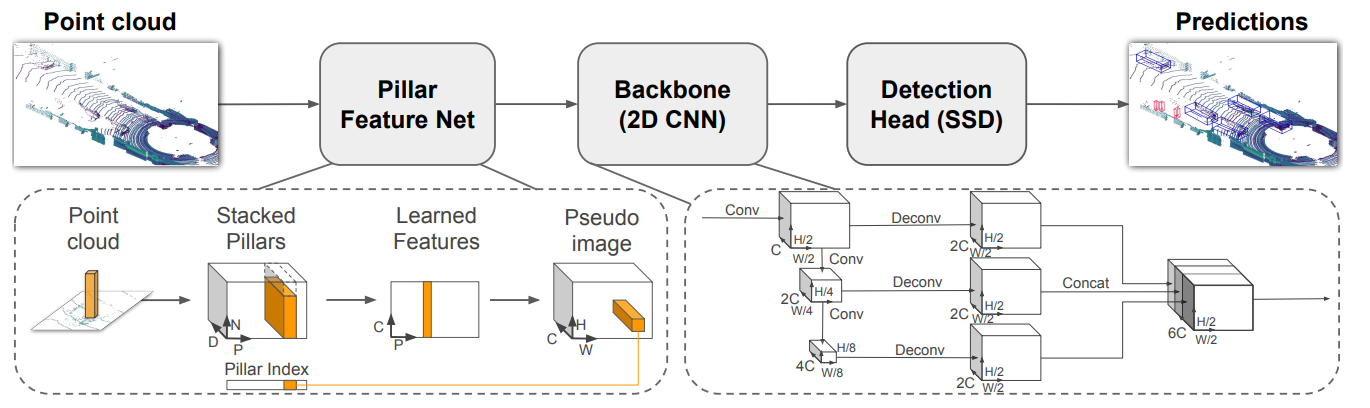
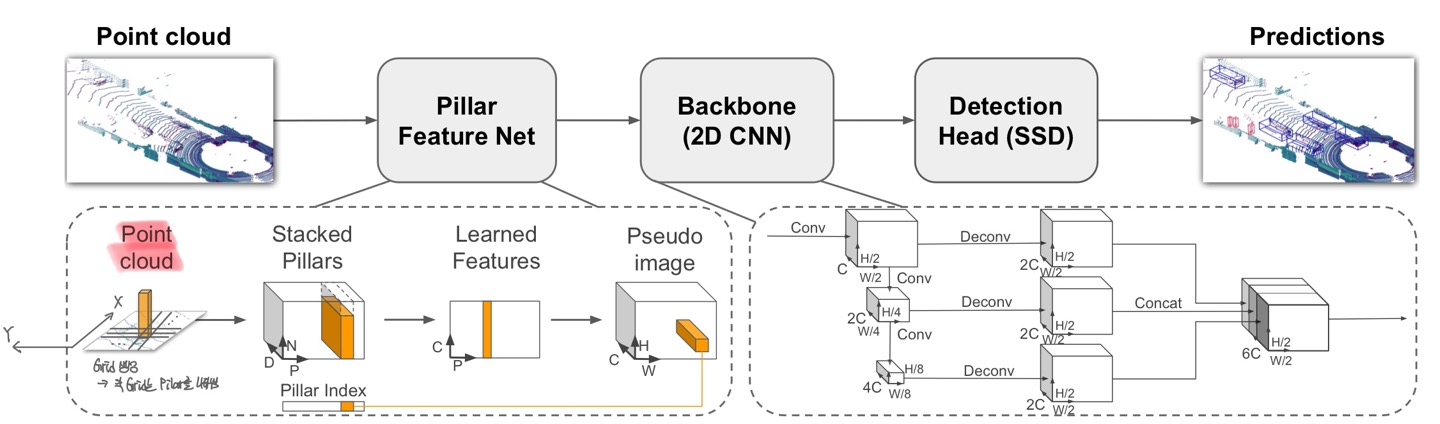
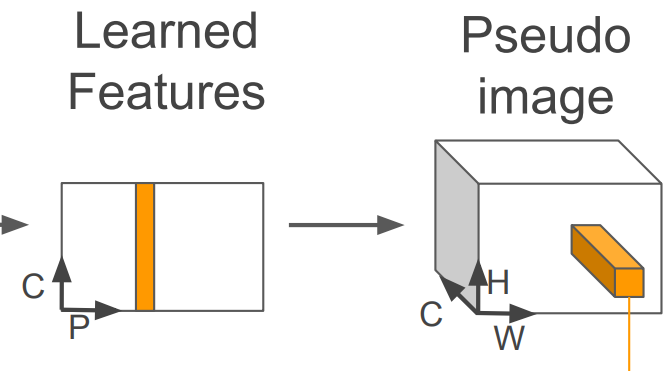
Pointcloud to Pseudo-Image
2D Conv Architecture를 적용하기 위해 3D PCD를 Psuedo-image로 변환해야 한다.
Point Cloud의 Point는 $l$로 정의되며, $l = (x,y,z,r)$로 해당 Point의 좌표 $x,y,z$와 반사계수 $r$로 정의된다. Point Cloud에 대해서 X-Y 평면에 균등하게 Grid를 생성하고, 각각의 Grid는 Pillar가 된다. 이때, a Set of Pillars $P$에 대해서 Pillar의 개수는 $|P|=B$로 정의된다. VoxelNet과 달리 Z 차원에 대해서 처리하는 과정이 존재하지 않기 때문에 Hyperparameter가 요구되지 않는다.
이후, 각 Pillar에 속하는 $l$은 $x_c, y_c, z_c, x_p, y_p$로 Augmented되며, $_c$는 각 Pillar에 속하는 모든 Point들의 중심과의 거리, $_p$는 Grid로 나눠진 각 Pillar의 중심과의 떨어진 거리를 의미한다. 따라서 최종적으로 각 Point $l$은 9차원의 정보를 가진다.
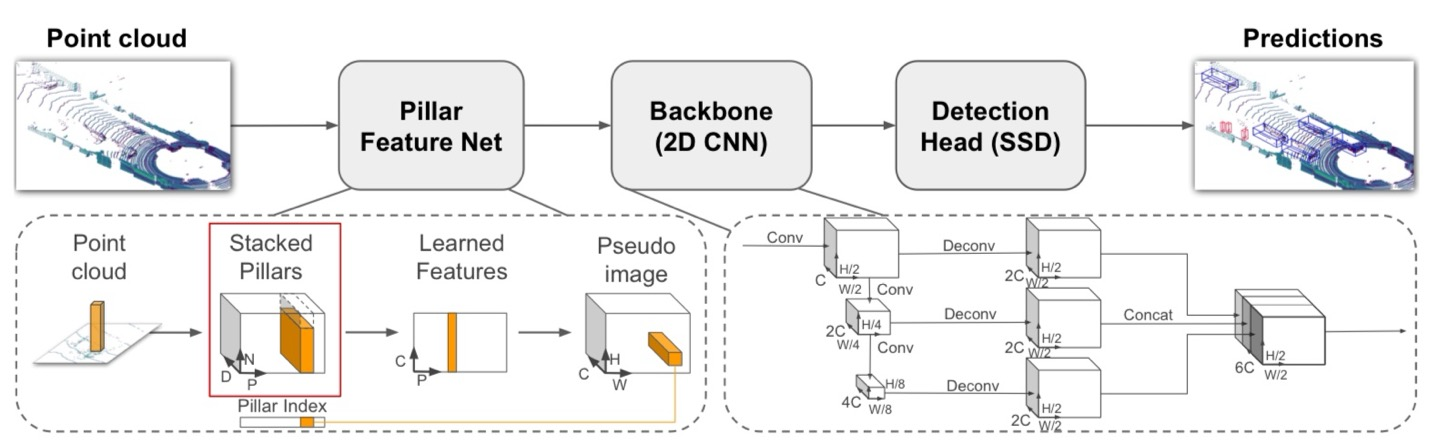
LiDAR는 매우 Sparse하기 때문에 Empty Pillars가 존재할 확률이 높다. 따라서 하나의 Set에 대해서 Non-empty Pillars를 $P$개, 각 Pillar에 대해서 최대 Points의 수를 $N$개로 제한하였으며, 최종적으로 Stacked Pillars는 $(D,P,N)$의 차원을 가지게 된다. 만약, 각 Sample이 $P$개 보다 많은 Pillars를 가지거나 각 Pillar가 $N$개보다 많은 Points를 가지게 된다면 Random-sampling을 진행하며, 적으면 Zero-padding을 수행한다.
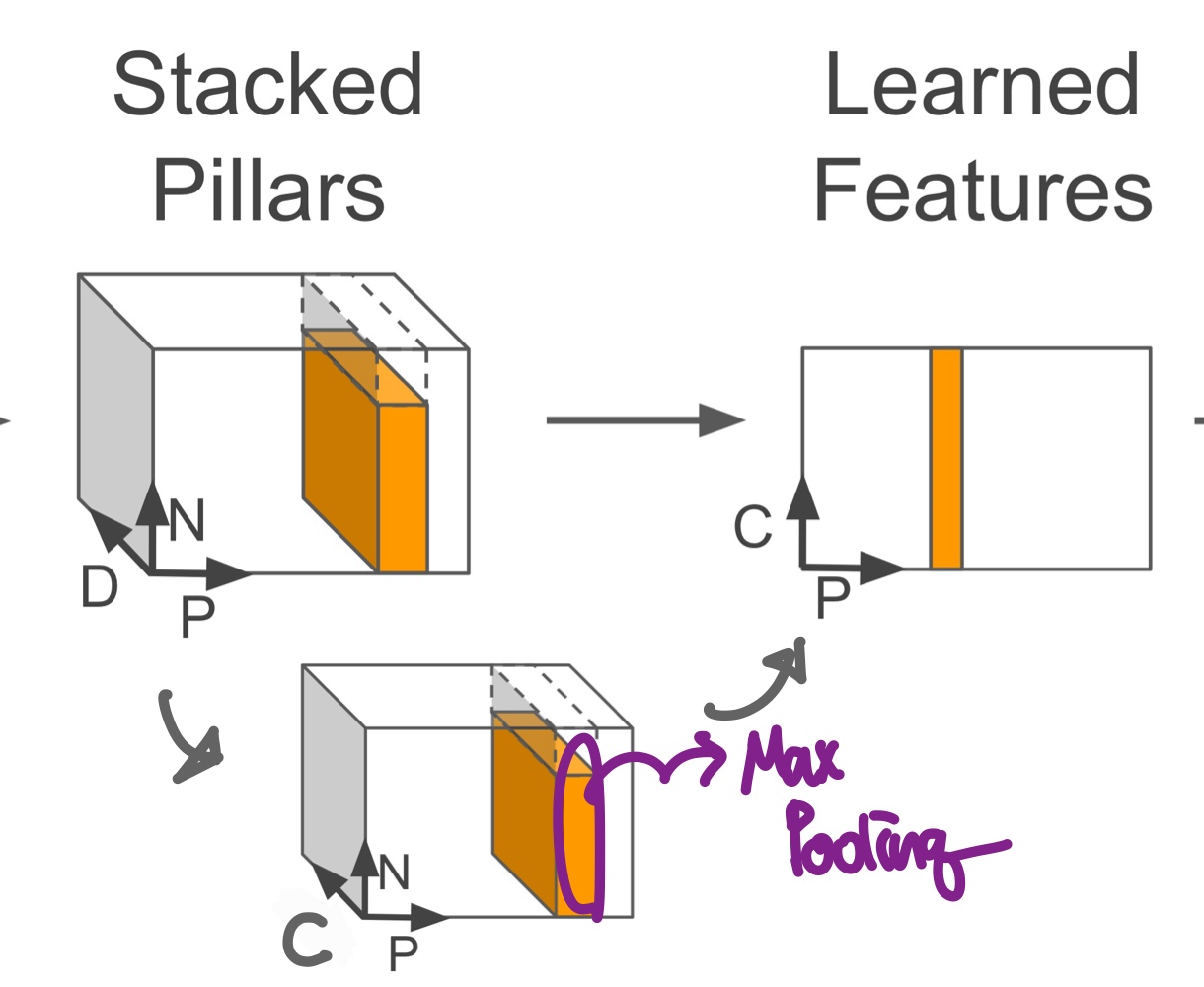
다음으로 모든 Point에 대하여 Batch Normalization, ReLU를 거쳐 $D$차원을 $C$차원으로 만들어 $(D,P,N) -> (C,P,N)$차원 변한을 통해 Feature Encoding을 수행한다. 이후 Channel 차원에 대해서 Max Pooling을 수행해서 각 Pillar를 대표하는 Feature Vector를 추출해 $(C,P,N) -> (C,P)$이 된다.
최종적으로 Psuedo-image를 생성하기 위해 $(C,H,W)$ 차원으로 변환한다.
이 과정을 어떻게 보면 "z"를 고려한 BEV같은 Pseudo-image를 생성했다라고 Rough하게 말할 수 있다.
따라서 2D Conv를 통해 인접한 Pillar 사이의 특징을 추출하여 객체를 검출할 수 있다.
Backbone
Backbone의 경우 2개의 Sub Network로 구성되어 있다.
보라색으로 표현되는 Top-down Network는 Sapital Resolution이 점점 작아지면서 Receptive Field가 커지게 된다. 즉, Global Feature를 추출하게 된다.
파란색으로 표현된 Top-down Network는 각각의 Feature Map을 Upsampling 하여 특정 크기로 맞춰준 뒤 Concatenation을 수행한다.
Down-sampling, Upsampling 과정에서 모두 BatchNormalization, ReLU를 거치며, 최종적으로 합쳐진 Feature Map은 서로다른 해상도의 Feature Map이 통합된 고해상도 Feature Map이 생성된다.
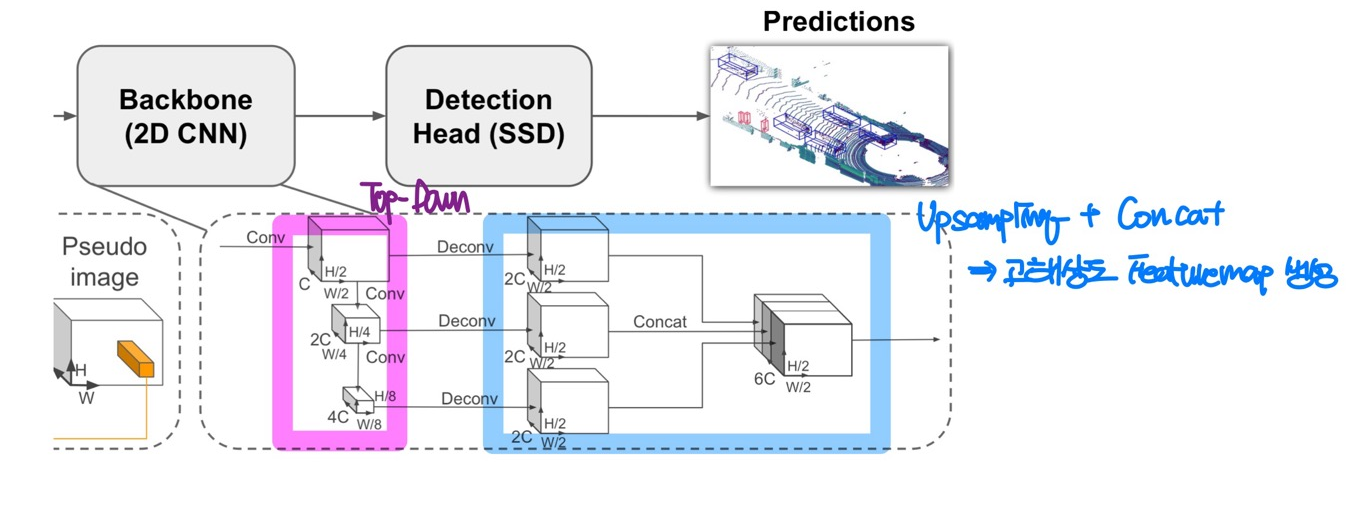
Detection Head
PointPillars에서는 SSD의 Detection Head를 사용하게 된다. 이때, Anchor 기반의 Box와 GT의 Matching은 2D IoU를 기반으로 계산된다. 즉, Z를 고려하지 않는다.
Loss
Experimental Setup
Dataset
KITTI Object Detection Benchmark Dataset으로 실험 진행. 해당 Dataset은 LiDAR PCD와 Image를 포함하지만, LiDAR PCD만 활용해서 PointPillars 학습을 진행하였다. 7481 Training, 7518 Test Dataset이 존재하기에, Training에서 3712 Train, 3769 Valid로 분리하였고, Test에서 784의 Valid, 6733의 Train으로 분리하였다.
Test Dataset으로 학습하고 Test를 진행한건가?
Class는 Car, Pedstrain, Cyclist로 구성되어 있으며, 오직 Image 상에 보이는 객체에 대한 GT만을 학습에 사용하였다.
또한, Car을 검출하는 Network, Pedstrain, Cyclist를 검출하는 Network를 다르게 학습시켰다.
Settings
Car, Pedstrain&Cyclist에 대한 RoI와 Anchor Size, Positive&Negative Matching Threshold를 서로 다르게 설정하였다.
Data Augmentation
GT에 대한 Lookup Table을 생성하여, 각 Sample에 대해서 각 Class마다 15,0,8개의 GT를 추가해주었다. 이는 LiDAR의 Sparse한 특성 때문에 빈 Pillar가 너무 많기 때문이다.
또한, 각 Point들에 대하여 회전, 이동, Noise를 추가하는 Augmentation을 수행한다.
Result
LiDAR만 사용하는 Model과 비교했을 때는 높은 mAP와 추론 속도를 보인다. 각 Class에 대해서 살펴보면, Car의 Easy Mode에서는 낮은 정확도를 보이지만, 그 외에는 모두 높은 성능을 보인다.

3D Oriented Boxes를 예측하기에, 방향성을 평가하는 Average Orientation Similarity(AOS) 평가지표를 비교 해 보면, PointPillars의 경우 AVOD-FPN, SECOND보다 모든 측면에서 높은 성능을 보인다. 하지만, Pedstrian의 성능이 낮음을 확인할 수 있다.
일반적으로 Image 기반의 기법이 2D 감지에서 높은 성능을 보이며, Orientation의 성능을 분석하기 위해 3D Box를 2D로 투영하는 경우 3D Pose에 따라 Box가 불안정해질 수 있기에 SubCNN이 높은 성능을 보이게 된다. 그럼에도 불구하고, PointPillars는 Cyclist에 대해 최고 성능을 보인다.

Pedstrain에 대한 낮은 성능을 정성적으로 평가 해 보면 다음과 같다.
Pedstrain과 Cyclist가 서로 오분류 되거나, 가로등 기둥이나 나무줄기와 같이 얇고 수직적인 환경적 요소와 혼동이 될 가능성이 크다.

Conclusion
본 논문에서는 PointPillars를 제안한다. 이는 LiDAR PCD를 기반으로 3D 객체 검출을 목적으로 하며, 높은 정확도와 빠른 추론속도를 가지고 있다.
'딥러닝 > 논문' 카테고리의 다른 글
| VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection (0) | 2025.02.05 |
|---|---|
| PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (0) | 2025.02.03 |
| Focal Loss for Dense Object Detection(RetinaNet) (0) | 2025.01.22 |
| SSD: Single Shot MultiBox Detector (0) | 2025.01.20 |
| You Only Look Once: Unified, Real-Time Object Detection(YOLO) (0) | 2025.01.19 |



