
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- AlexNet
- YoLO
- ubuntu
- r-cnn
- dynamic programming
- BFS
- image processing
- 강화학습
- 백준
- Reinforcement Learning
- NLP
- 머신러닝
- 그래프 이론
- CS285
- hm3d
- C++
- deep learning
- dfs
- GIT
- CNN
- 딥러닝
- MySQL
- LSTM
- DP
- UC Berkeley
- RL
- opencv
- Python
- hm3dsem
- machine learning
- Today
- Total
JINWOOJUNG
Deep Reinforcement Learning 본문
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar
수강 후 정리를 위한 포스팅입니다.
모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다.
Before This Episode
https://jinwoo-jung.tistory.com/35
Value Function Approximation
본 게시글은 인하대학교 유상조 교수님의 Reinforcement Learning Tutorial Seminar 수강 후 정리를 위한 포스팅입니다. 모든 포스팅의 저작관은 유상조 교수님에게 있음을 사전 공지합니다. Before This Episode
jinwoo-jung.tistory.com
이전까지의 내용을 정리해 보자. 기존 Tabular 방식의 Update는 공간적 문제, Update 되지 않는 State/Action 문제 등이 있기에 State&Action을 Input으로 하면 Parameter $\theta$(지난 시간에는 $w$)를 통해 $\hat{v}(S), \hat{Q}(S,a)$가 나오고 해당 Output이 $V_{\pi},Q_{\pi}$와 같아지는 방향으로 $\theta$를 학습시키는 VFA를 배웠다.
이때, 목적함수 $J(\theta)$는 (Action Value 예시) MSE = $E[{Q_{\pi}(S,a) - \hat{Q}(S,a,\theta)}^2]가 최소가 되는 $\theta$를 구하는 것으로 정의되었다. 하지만 수많은 경우를 실제 해보지 못하기 때문에 평균이 아닌 Sample 마다 진행하는 SGD, Batch Size마다 진행하는 BGD가 있었다.
그리고 True-Value $Q_{\pi}$를 알지 못하기 때문에, 우리는 SARSA, Q-Learning 각 방식에 맞게 대체해서 적용하였다.
그중에서 Q-Learning 방식의 경우 True-Value를 다음과 같이 대체한다.

State $S_t$가 Input으로 주어지고 FA에 의해 나온 Prediction $\hat{Q}(s_t, a_t | \theta)에 의한 $ \varepsilon $-greedy 방식으로 선택된 Action $a'$을 진행하고, 얻어진 Reward $r$, 변화된 State $s_{t+1}$을 얻는다. 이를 다시 Input으로 하여 $max_a_{t+1}Q(s_{t+1},a_{t+1})$을 구하고 계산된 값으로 Update를 진행한다.

이러한 Deep Q-Learning의 Sudo-Code를 살펴보면 위에서 설명한 과정이 녹아져 있다.
하지만 문제점은 지난 강의에서도 살펴봤듯이 Nonlinera FA(such as a neural network)에서는 Convergence의 문제가 있다. 따라서 Deep Q-Learning에서 강화된 Deep Q-Network(DQN)이 등장하였다.
DQN

DQN은 더 깊은 층을 구현하고, Sample들 사이에서 상관관계를 최소화 하기 위해 Replay Memory를 사용한다. 가운데에 보면 높은 상관관계(Ex 시간의 연속성)를 지니는 데이터를 이용하여 추론할 경우 True-Value에서 벗어난 경향을 보임을 알 수 있다. 하지만 오른쪽은 상관관계가 적은 데이터를 이용하여 추론하면, 더 적더라도 전체 데이터를 기반으로 추론한 값과 유사함을 알 수 있다.
또한, 위 식에서 정의된 Loss Function을 보면 Target($R_{t+1} + \gamma max_{a'} \hat(Q)(s_{t+1},a'|\theta)}$)과 비교하는 $\hat{Q}(s_t,a_t|\theta$ 모두 $\theta$를 이용하기에 Update할 때 마다 Target 역시 매번 변화하여 Update의 의미를 상실하게 된다. 따라서 Target-Value 계산 시 $\theta$를 고려하지 않는 다른 Value로 교체한다.
Reduce Correlation

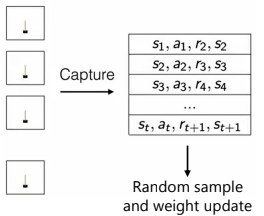
상관관계를 줄이기 위해, Terminal State 까지 진행한 $<s,a,r,s'>$을 모두 저장한다. 이후 연속적인 Data가 아닌 Random Sample을 선정하여 Weight를 Update 하는 방향으로 진행한다.

Sudo-Code를 보면 쉽게 알 수 있는데, $t=1~T$까지 반복하면서 모든 Info를 저장한 후, Random Sample을 선택하여 Update함을 알 수 있다. 현재는 minibatch로 진행하지만, 매 Step마다 진행도 가능하다.
Target of loss function


앞서 언급한 것 처럼, Weight Update 시 Target 역시 Parameter $\theta$에 의존적이기 때문에 영향을 미친다. 따라서 이전 단계의 $\theta$인 $\theta^-$를 Target의 Parameter로 설정하고 매 Batch에 대한 Update가 끝날 때 마다 $\theta^-$를 Update 한다. 위 슬라이드에서 $\phi'$가 $\theta^-$이다.
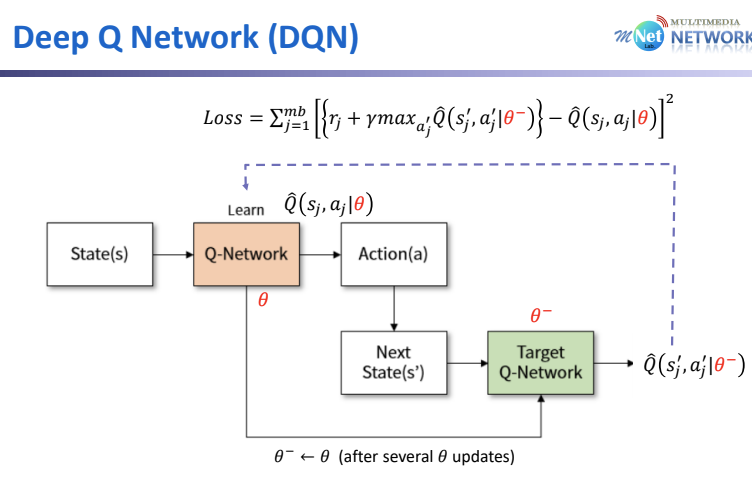
위와 같은 프로세스로 동작 시 Target은 $\theta$에 의존적이지 않으므로, Parameter $\theta$를 정확하게 Update 가능하다.
만약 둘다 동일하다면, Update가 진행됨과 동시에 Target 역시 변하여 정확한 학습이 불가하다. Sudo-Code는 아래와 같다.

'Reinforcement Learning' 카테고리의 다른 글
| [RL] CS285: Lecture 02. Supervised Learning of Behaviors(1) (0) | 2025.12.14 |
|---|---|
| [RL] CS285: Lecture 01. Introduction (0) | 2025.12.08 |
| Value Function Approximation (0) | 2024.02.04 |
| Model-based RL (1) | 2024.01.28 |
| n-Step Bootstrapping (1) | 2024.01.22 |



